Query Kafka Topics with SQL: Stop Duplicating Your Data
Query Kafka topics with SQL using PostgreSQL endpoints, Iceberg, and Parquet—eliminating data duplication for analytics and AI/ML pipelines.

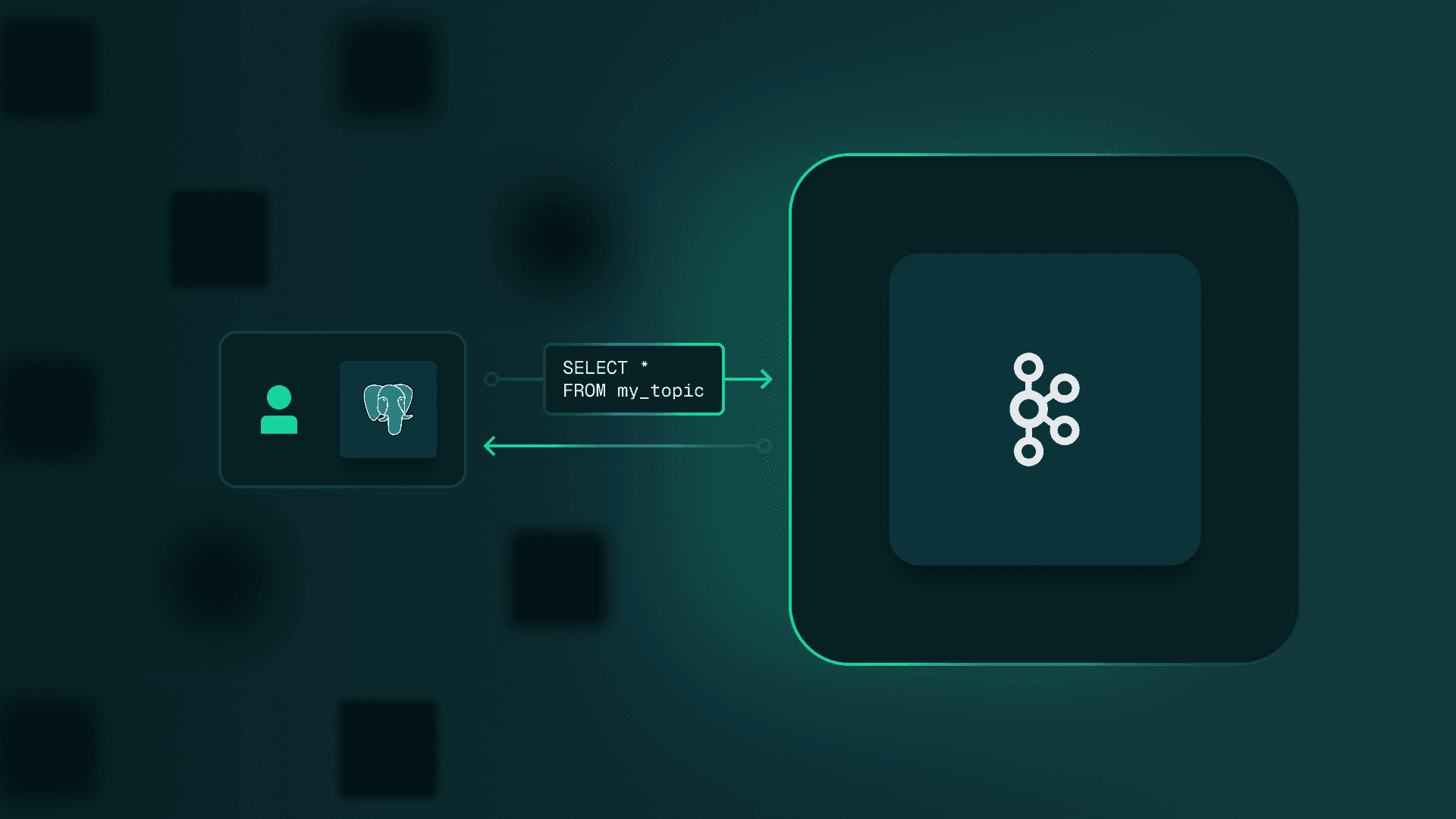
Large organizations use Apache Kafka to exchange massive volumes of data. The problem: you can't easily query these messages. Someone always has to duplicate the data from Kafka topics to a regular database just to run queries. Direct SQL access to Kafka would eliminate this entire layer.
TL;DR
- Apache Kafka excels at data exchange but doesn't natively support queries.
- Querying Kafka topics usually requires data duplication that creates consistency and security problems.
- SQL-compatible endpoints for Kafka let data engineers, analysts, and product teams access the same data without building separate pipelines.
Kafka's Role in Modern Data Architectures
Kafka was open-sourced in 2011 when massive databases and big data were king. Since then, streaming data patterns have matured significantly.
Today, Kafka primarily moves data to destinations everyone can work with: databases, data warehouses, or data lakes (PostgreSQL, ClickHouse, Elasticsearch, Snowflake). Analytics teams query these systems. Engineers build dashboards and ML models from them.
Kafka's default data retention is just a few days. Most organizations use it only for real-time capabilities, not historical analysis.
Combined with stream processing (Kafka Streams, Apache Spark, Apache Flink), Kafka powers streaming ETL: capture, transform, and load data in real time rather than scheduled batches.
This architecture works. But it has one significant drawback: data accessibility.
The Data Accessibility Problem
Apache Kafka often handles all organizational data before routing it to other applications. This data remains barely accessible to non-developers: data scientists, analysts, and product owners.
Even developers struggle. No widely adopted query language like SQL exists for Kafka data. You need command-line tools to analyze messages. That only goes so far.
Organizations want consistent data access for everyone, regardless of technical background. Teams shouldn't need to learn complex new tools to work with data on a new project.
Platforms like Conduktor increase visibility into Kafka ecosystems without requiring everyone to become Kafka experts.
Why Duplicating Kafka Data Creates Risk
Organizations depend on data engineering teams to build pipelines and ETL to make Kafka data accessible. Teams use change data capture (CDC) tools like Debezium to move data outside Kafka.
CDC with Debezium can work, but it creates problems, especially with data spread across multiple tables. This approach often requires installing and configuring Kafka Connect.
Data duplication puts consistency at risk. It also dilutes ownership, security, and responsibility.
Kafka's ACID Capabilities and Their Limits
In 2018, Martin Kleppmann demonstrated that you can achieve all ACID requirements (atomicity, consistency, isolation, durability) in Kafka by building stream processors.
Kafka supports exactly-once transactions. Apache's KIP-939 proposal adds two-phase commit (2PC) protocol support for distributed transactions with other databases.
Kleppmann's conclusion still applies: for ad-hoc queries, you must move your data to a real database.
Six years later, this limitation slows down everyone who wants to work with Kafka.
The Cost of Data Fragmentation
Organizations have tons of data of varying quality in Kafka and in databases. Rules and best practices differ between systems. Teams quickly lose track of what data lives where. Source of truth becomes unclear. This is a data mess.
Duplicating data from Kafka to databases adds complexity. Security models differ fundamentally between systems. Kafka has one way of protecting data; databases have another. This mismatch is hard to reconcile. Add data masking or field-level encryption requirements, and it becomes nearly impossible.
This is how data leaks happen. In March 2024, a French government breach exposed up to 43 million people's data. These incidents reveal deficiencies in skills, consistency, and ecosystem maturity.
The rapid multiplication of data products aggravates fragmentation. This proliferation creates data silos containing stale or mismatched data. Each operates in isolation. Ad-hoc pipelines built outside a cohesive governance framework leave organizations vulnerable to inaccuracies and inconsistencies.
SQL as the Query Interface for Kafka
SQL ranks 6th on the TIOBE index. 40% of developers use it globally.
PostgreSQL has emerged as the leading database protocol. Every data vendor wants compatibility with it.
Tools like Grafana, Metabase, Tableau, DBeaver, and Apache Superset connect to PostgreSQL-compatible endpoints. A Kafka platform providing such an endpoint for any topic lets you use these tools for data visualization and introspection.
SQL provides a foundation for a unified data ecosystem with Kafka as the single source of truth. PostgreSQL's broad compatibility, open-source nature, and straightforward setup make it a practical choice.
Conduktor adds SQL capabilities to Kafka. This reduces the need for data pipelines and replication. It improves performance and cost efficiency, simplifies governance, and reduces security failures.
This approach integrates data engineers into product teams rather than isolating them in silos with separate data roadmaps.
SQL, Parquet, and Iceberg for AI/ML Pipelines
SQL works well for ad-hoc analysis, dashboarding, and data pipelines. It doesn't handle the massive volumes required for data science and AI/ML.
Apache Parquet and Apache Iceberg solve this problem. They provide column-based storage and pushdown filter optimizations for querying large datasets efficiently. Data scientists use them with Apache Spark, Pandas, Dask, and Trino.
As we noted in our Kafka Summit London 2024 review, Kafka serving as the single source of truth is becoming reality. Confluent announced Tableflow, which materializes Kafka topics as Apache Iceberg tables without requiring separate data pipelines.
Querying Kafka Topics with Conduktor
Conduktor's SQL syntax lets you query topics in Kafka directly, using Kafka's real-time data capabilities to meet business requirements. Kafka and Conduktor support file formats like Parquet and Iceberg for AI/ML workloads.
This approach builds data-driven products without duplicating data across different stores, creating a more efficient and secure data ecosystem.
To make your data more accessible while maintaining governance and security, book a Conduktor demo.