Map Kafka Costs to Teams and Projects with Chargeback
Track Kafka costs by team, project, and environment—not just partitions. Conduktor Chargeback maps service accounts to real business units.

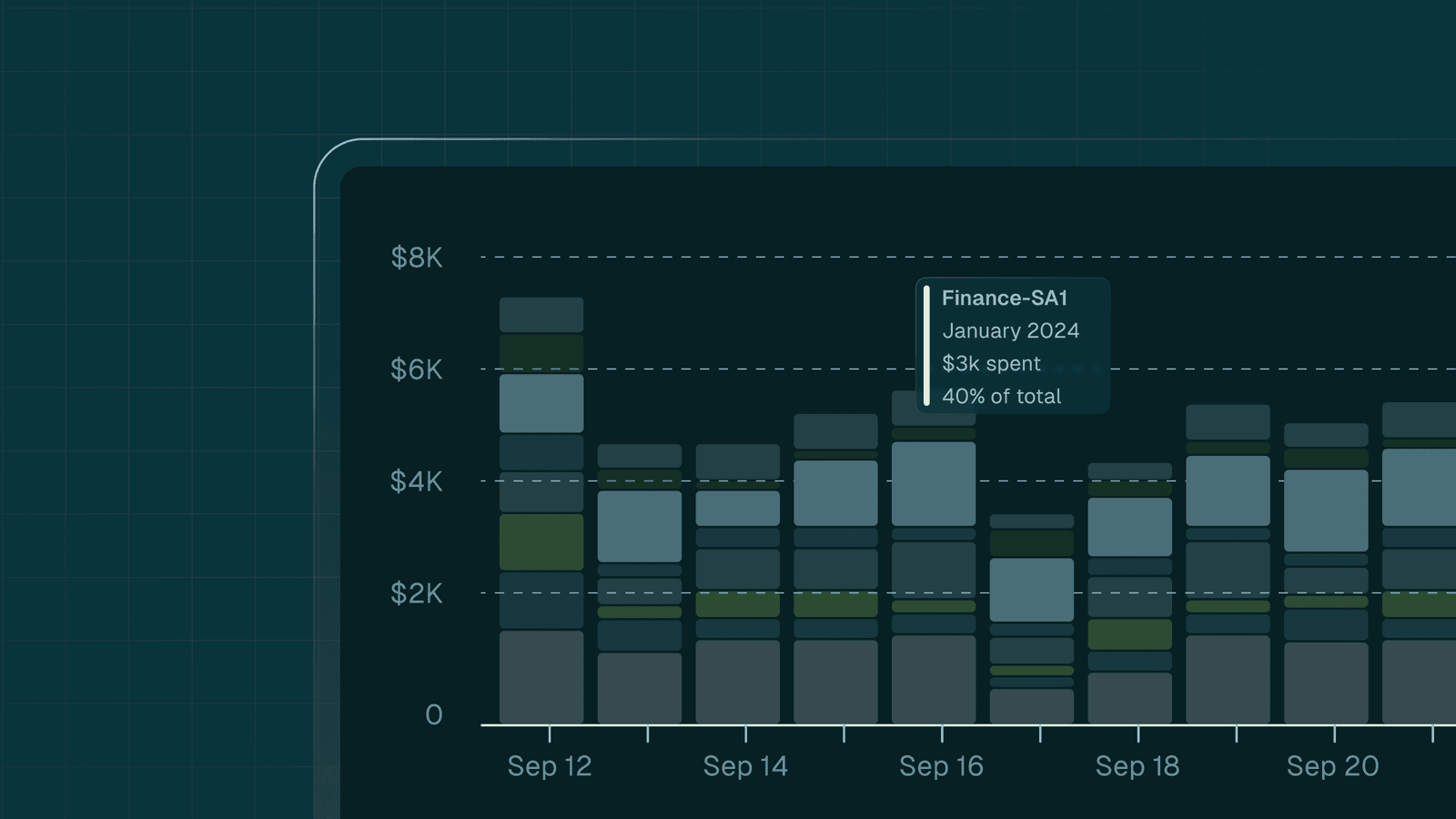
Most teams track Kafka costs using disk size and partition counts. These metrics are accessible and map directly to Kafka cost structures. But they answer the wrong questions.
Disk and partition metrics tell you nothing about:
- Who produced or consumed the data
- Which topics belong to which projects and teams
- Which teams drive the highest costs
Service Accounts Show Usage But Not Ownership
The next step is to track service accounts. These credentials capture how much data moved, who connected to what, and metrics like bytes in/out and messages produced/consumed.
Service accounts still fall short. They have no built-in way to correlate usage to teams, projects, or environments.
Without this context, you cannot:
- Investigate anomalies in Kafka costs
- Find expensive projects
- Identify unused infrastructure
- Determine topic and cluster ownership
Service accounts are also opaque to finance teams. Raw technical identifiers make budgeting and forecasting difficult for anyone unfamiliar with your Kafka architecture.
The data exists. The context to make it useful does not.
Chargeback Adds Business Context to Kafka Usage
Conduktor Chargeback is now generally available as part of the Scale+ package. It supports user-defined labels that map service accounts to business units.
Add metadata labels to service accounts. Chargeback automatically groups usage into categories you define: team, product line, project, environment.
This transforms technical data into business data:
- Allocate costs by product line
- Separate staging and production environments
- Track project-specific consumption
- Give teams ownership of their Kafka footprint
Example: Outdoor Retailer with Five Product Teams
An online outdoor retailer ships internationally with high order volume. They need real-time order tracking, minute-accurate inventory updates, dynamic pricing, and personalization. Kafka powers these functions.
Their environment:
- Dozens of microservices across five teams: checkout, product search, recommendations, order tracking, returns
- Shared Kafka clusters for dev, staging, and prod
- Mix of self-hosted and managed Kafka (Confluent, Aiven)
With Chargeback, finance tags each service account:
- team=checkout
- env=prod
- project=cart-refactor
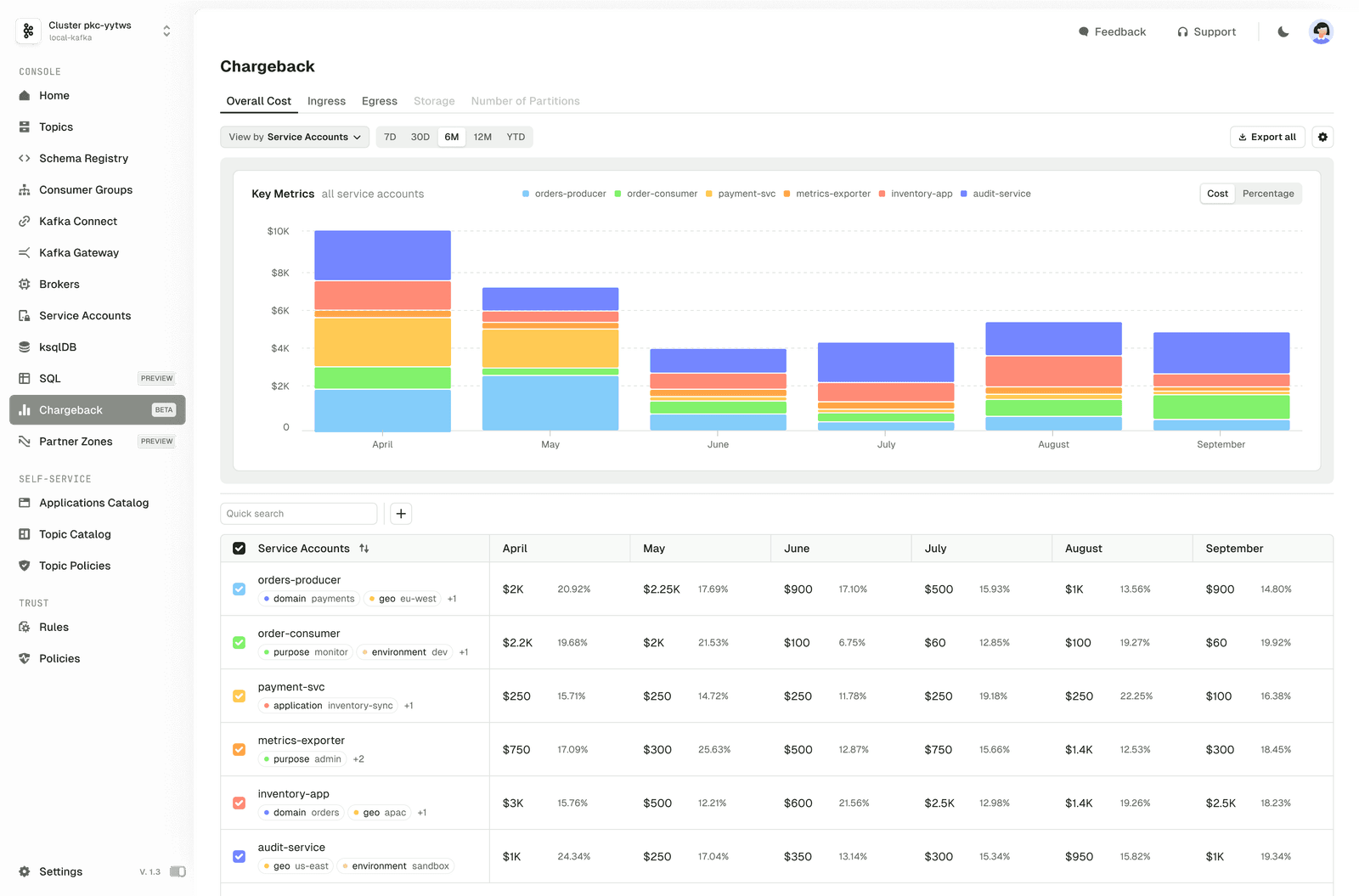
Fig. 1. Service accounts grouped with labels by team, environment, and project.
Finance can now answer:
- Which infrastructure drives the highest Kafka costs? Which teams own it?
- Why do staging and production costs differ?
- Which projects push the most traffic this quarter?
- Which clusters see low traffic but high costs? What is their partition count?
With this context, finance can optimize spending: find expensive but underperforming infrastructure, identify teams exceeding budgets, and cut unnecessary costs.
Unified Service Account Management Across Kafka Providers
Organizations running Kafka on multiple providers (Confluent Cloud, Aiven, self-hosted) struggle to consolidate service account data.
Chargeback lets you monitor, manage, and tag service accounts across all providers via API:
- Centralized visibility into all service accounts
- Organize accounts by team or project
- Reduce config drift and manual cleanup
Kafka Costs Aligned to Business Structure
Chargeback brings platform and finance teams onto the same page.
You can track Kafka usage by project, team, or environment. This enables better accountability, lower costs, and informed decisions about infrastructure spending.
To try Chargeback, sign up for a free demo.