Automate Kafka Configuration at Scale with GitOps
Complex infrastructure calls for automation. GitOps streamlines Kafka configuration and scales deployments efficiently.


Managing distributed systems like Apache Kafka requires a scalable and automated approach. Manual intervention does not cut it. Kafka GitOps and infrastructure as code (IaC) cannot be an afterthought.
According to Confluent's 2023 Data Streaming Report, 74% of IT leaders cite inconsistent use of integration methods and standards as a significant hurdle to advancing data streaming.
As deployments grow, platform teams struggle to track configurations, updates, and dependencies. Development teams face their own problems: identifying ownership, discovering existing resources, and sharing data across teams.
GitOps and IaC bring consistency, standardization, and agility to Kafka users.
Summary
- Manual configuration cannot keep up with scaling Kafka deployments.
- Kafka GitOps automates resource and configuration management in Apache Kafka.
- Kafka client configurations are a minefield. Policies and tooling help you implement guardrails at scale.
- Conduktor provides a framework for consistency and standardization when scaling.
What Kafka GitOps Covers
In the context of Kafka, GitOps applies to deployment automation, resource configuration, access provisioning, and client configurations.
Automating these processes lets developers ship changes faster, introduces governance best practices, and reduces the burden on platform teams running Kafka operations.
Why Manual Configuration Management Fails
A limited number of Kafka projects with focused scopes is manageable for ops and platform teams. They typically handle resource requests like topic creation, partition modification, schema registration, and access requests through Jira tickets and manual provisioning.
As adoption increases, requests multiply and infrastructure complexity grows. The team needs to scale to support it, but manual methods become tedious and inefficient.
Ad hoc changes increase the risk of human error, inconsistencies, and misconfigurations. A simple typo in an ACL entry can lead to failures or unauthorized consumers.
The manual process lacks version control, traceability, and transparency. Automation solves these problems.
Automating Resource Management with GitOps
Imagine handling over 100 TLS certificates, 3,500 Avro schemas, 1,000 topics, and 5,000 ACLs.
Doing this manually guarantees a mess of inconsistent topic names, over-provisioned partitions, and no uniform strategy for managing broker, producer/consumer, and security configurations.
To scale adoption beyond a critical mass of teams, resources, and projects, you need a GitOps process.
A GitOps configuration-as-code approach automates the management of topics and ACLs using configuration files that define resources and access, similar to how Terraform provisions infrastructure.
Why IaC Tools Are Not Enough for Kafka at Scale
Handling declarative configuration in Kafka with tools like Terraform works at small scale. As you grow, you need a more specialized solution.
This becomes evident in issues like topic management and cluster creation in production. Conduktor provides a comprehensive way to streamline Kafka GitOps.
Configuration Management with GitOps
Topics, schema subjects, connect configurations, and security configurations can be numerous and diverse. You need a way to manage them efficiently and without errors so that growing configurations do not degrade performance and reliability.
GitOps lets you store Kafka configurations in repositories as YAML or JSON files. The example below shows a Kafka topic represented as YAML for use with Conduktor:
---
apiVersion: kafka/v2
kind: Topic
metadata:
cluster: lzp-prod
name: click.event-stream.avro
spec:
replicationFactor: 3
partitions: 3
configs:
min.insync.replicas: '2'
cleanup.policy: delete
retention.ms: '60000'Storing resource configurations as code lets you manage changes to your Kafka infrastructure through Git pull requests. This practice relies on three principles: review, approval, and audit trails.

This results in a transparent approach with self-documenting artifacts and shared understanding of the Kafka infrastructure. It encourages communication and knowledge sharing between teams.
How GitOps Prevents Costly Misconfigurations
An IaC approach without control over configurations leads to a Wild West scenario. You need automated policy enforcement in your CI/CD pipeline.
As a platform administrator, you want to globally restrict expensive Kafka configs such as:
- Replication factor of 3 to ensure high availability and fault tolerance.
- Max partitions of 10 to prevent excessive resource consumption.
- Max retention of 1 day to limit storage costs.
- Topic naming that follows internal standards for semantic clarity.
Here is a Kafka topic policy that implements the above in Conduktor:
---
apiVersion: "v1"
kind: "TopicPolicy"
metadata:
name: "prod-topic-policy"
spec:
policies:
spec.replicationFactor:
constraint: OneOf
values: ["3"]
spec.partitions:
constraint: Range
max: 10
min: 3
spec.configs.retention.ms:
constraint: Range
max: 86400000
min: 60000
metadata.name:
constraint: Match
pattern: ^click\.(?[a-z0-9-]+)\.(avro|json)$Resource configuration policies can be stored as IaC and orchestrated as checks within CI/CD workflows.
This enables automated provisioning of Kafka resources without the risks of complex configurations.
By design, it adds a comprehensive Kafka governance layer, minimizing deployment errors, reducing manual effort, and introducing a safe framework for scaling.
Centralized vs. Decentralized Configurations
IaC enables platform teams to push responsibility to domain owners for managing their Kafka configurations. This removes dependencies on platform teams, who rarely have the business context behind specific Kafka configurations.
Empowering domain owners lets platform teams focus on providing tools, frameworks, and workflows to support IaC implementation. This shift fosters accountability and ownership, which is fundamental for scaling. If it takes more than a few hours to create a topic, you have a bottleneck.
An IaC approach raises questions about how to structure Kafka operations:
- Centralized approach: One repository stores Kafka configurations for the whole company.
- Decentralized approach: Multiple repositories for each team or domain.
The right choice depends on your company structure and the trade-off between agility and governance requirements. Consider these pros and cons:
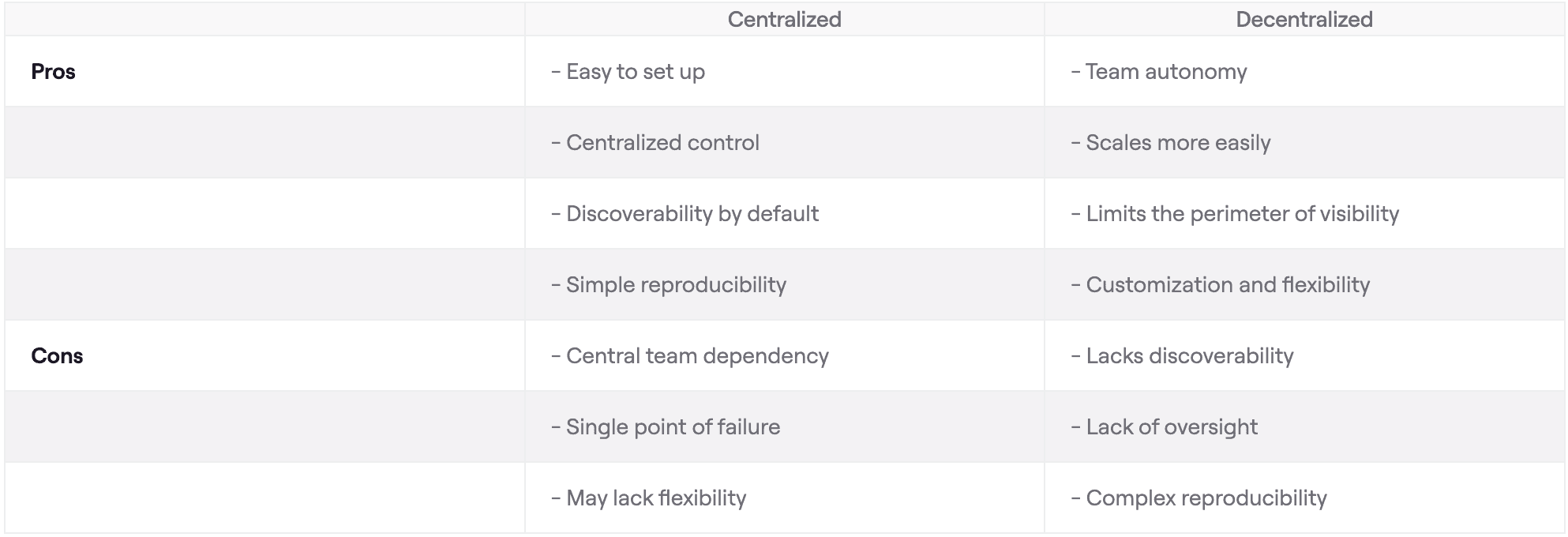
A hybrid approach often works best: teams manage less critical configurations while the most critical ones are managed centrally for consistency and compliance.
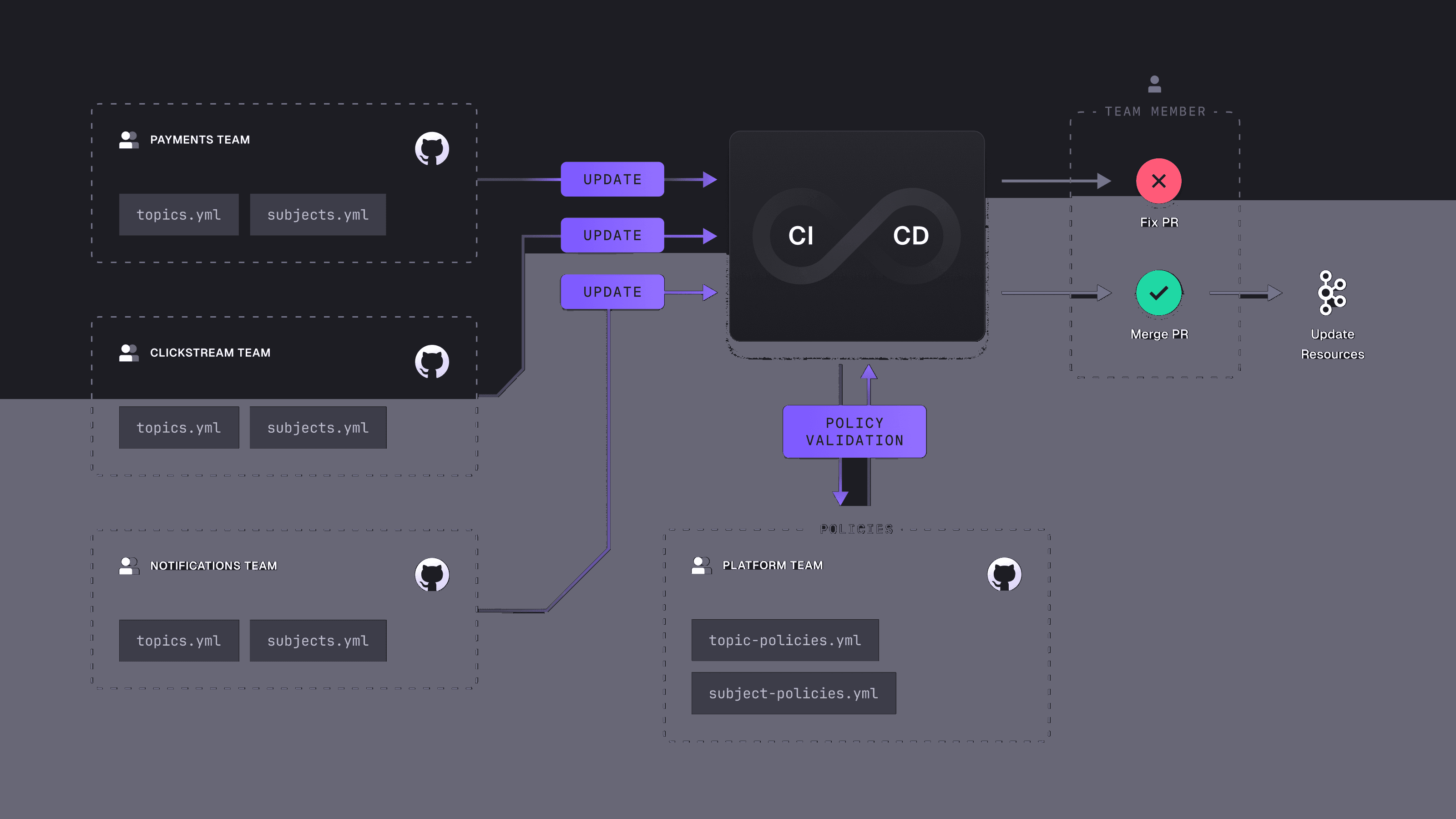
Resource Policies in CI/CD Have Limitations
In the Kafka ecosystem, you must look beyond resource configurations. Streaming applications connect directly to Kafka, and their behavior and configuration typically do not follow GitOps principles.
There are over 100 client configuration settings in Kafka. Using default settings may not seem problematic at first, but you need to consider the impact on your network, disk, quality of service, and costs as you scale.
Below is an example of a Kafka client configuration. The Kafka Options Explorer provides a complete list.
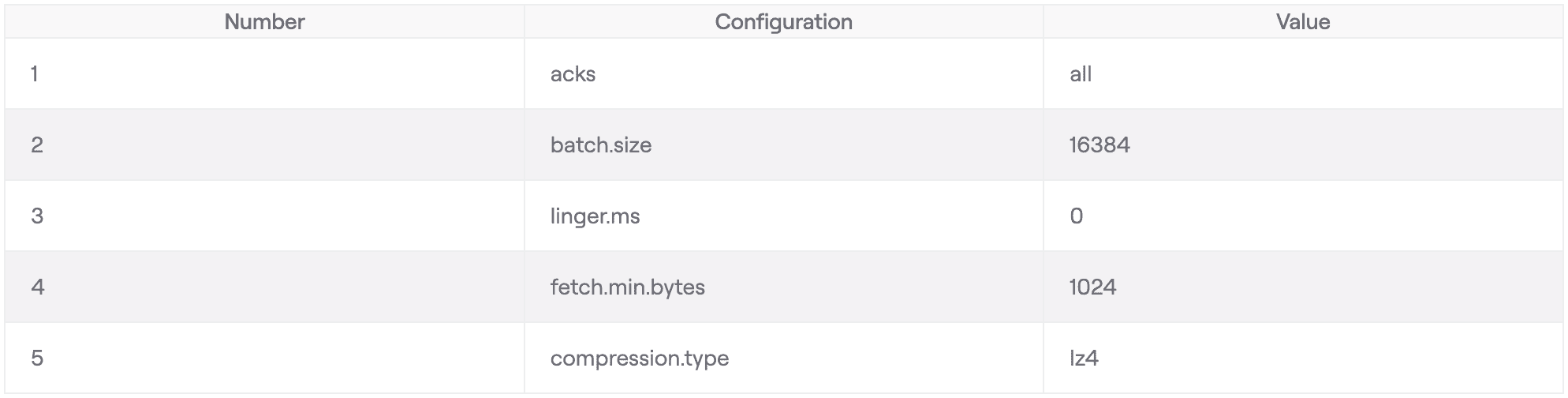
This shows a configuration with default Kafka client settings for batch.size and linger.ms, a custom setting for compression.type to enhance performance, and acks set to all for maximum reliability.
Managing Client Configurations Safely
Kafka client configurations are a minefield. Developers cannot reasonably track the intricacies and consequences of each setting.
One poorly informed configuration can severely impact your entire Kafka platform and underlying applications.
With automation, you can prevent mistakes in client configurations:
{
"config": {
"acks": {
"value": [ 0, 1 ],
"action": "BLOCK"
},
"compressions": {
"value": ["NONE"],
"action": "BLOCK"
},
"recordHeaderRequired": {
"value": true,
"action": "BLOCK"
},
}
}This policy on client configurations enforces:
- Blocking acks of 0 or 1, requiring -1 for highest durability and reliability
- Requiring a compression format to conserve storage and reduce network bandwidth
- Requiring a record header for message routing and filtering
Such policies let teams operate autonomously while maintaining control of producer/consumer settings at a global level. They are an essential part of Kafka GitOps.
Enforcing Client Configuration Best Practices at Scale
GitOps traditionally does not govern configurations of applications that connect directly to Kafka. You can solve this architecturally with a proxy.
Conduktor Gateway is an intermediary proxy for handling Kafka requests before forwarding them to the broker. It evaluates requests against client configuration policies and can manipulate them, for example by adding field-level encryption before sending them on.
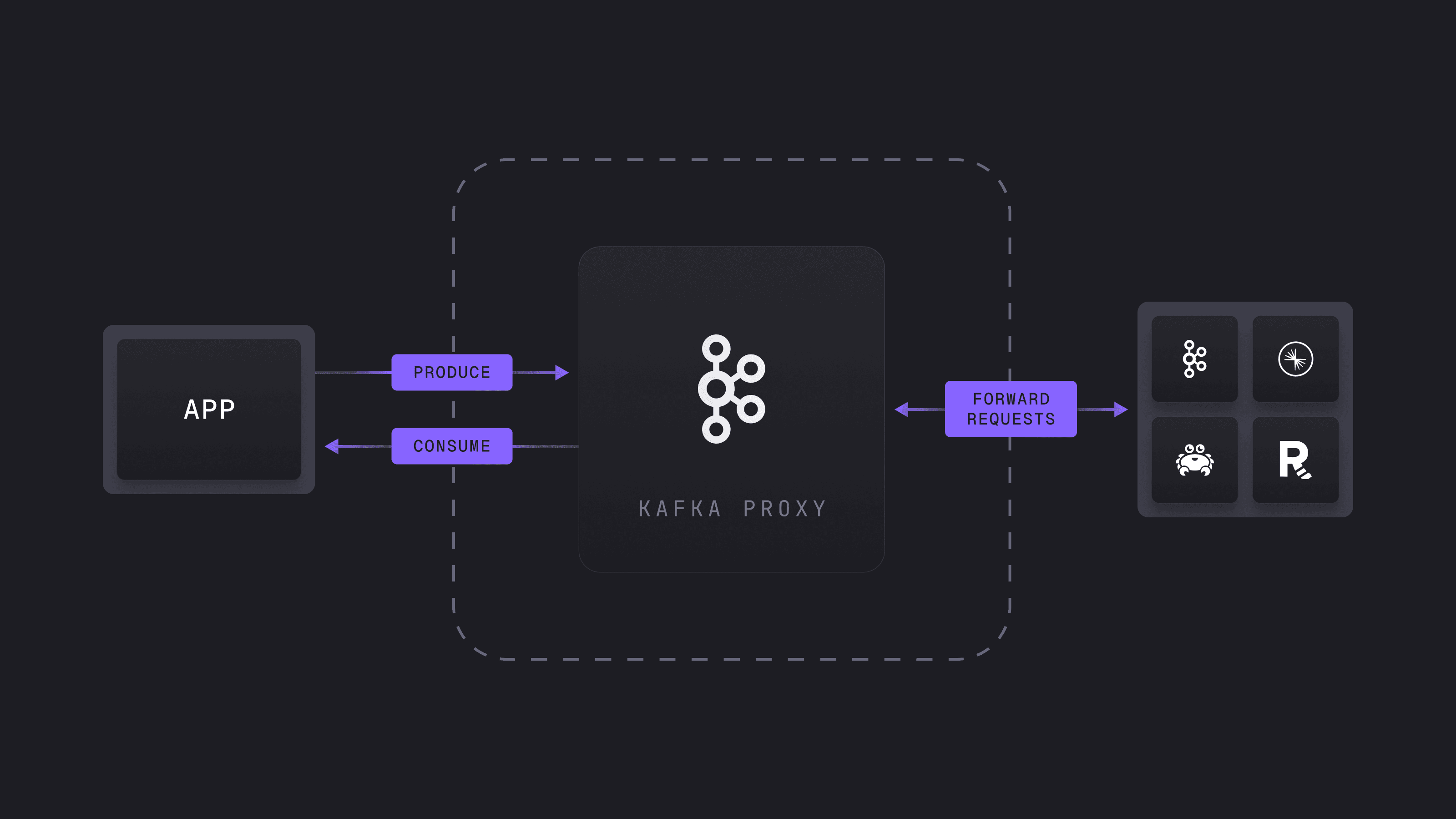
Inspired by GitOps principles, the proxy centralizes configuration validation, bringing consistency and compliance across clients without forcing changes to each client application.
This reduces the risk of one misconfigured client causing problems for others and the maintenance overhead of keeping client libraries up to date.
Conduktor's proxy is stateless and scales horizontally. Add more instances and distribute traffic with a load balancer.
These demos can get you started with Conduktor Gateway. Explore the documentation for more scenarios.
GitOps Brings Consistency and Agility to Kafka
As Kafka adoption scales, new applications bring new requirements, and teams face more configuration and management complexity.
A GitOps approach to managing Kafka resources, client configurations, and rules increases automation, traceability, and collaboration.
To scale your Kafka deployment with consistency and standardization, book a Conduktor demo.
You can also join the community. Our team will chat about how Conduktor can help you adopt Kafka GitOps at scale.