Why ML Models Fail in Production: The Training Data Mismatch Problem
Mismatched training and production data cripples AI models. Real story from a UK lender shows why Conduktor Trust prevents ML pipeline failures.


Operational data powers real-time decisions, fraud detection, personalization, and predictive maintenance. But using it effectively for AI is harder than it looks.
I saw this at a UK-based digital lender focused on small business loans. Speed was our edge. We automated loan underwriting with ML models running on real-time Kafka streams. Borrowers could be approved, signed, and funded in minutes. Everything depended on data pipeline quality.
Models Trained on Polished Data, Deployed on Raw Data
Training followed standard ML workflows: collect historical datasets, clean and enrich them, run simulations, tune parameters. The problem came at deployment.
Production models ran on real-time operational data: raw, inconsistent, fast-moving. But training datasets came from our analytical environment, where data had been ETL'd, transformed, normalized, and cleaned. The models learned from a polished version of reality that didn't exist in production.
That disconnect was expensive. Engineers had to study the ETL pipelines that produced training data, then build wrapper logic to replicate those transformations in real-time. Hard to maintain. Required constant testing. Every change was risky.
The system designed for speed got slowed by complexity. Deploying new models took longer. Debugging got harder. Conservative testing and change control set in. Keeping models trained on the same data they'd operate on became increasingly expensive.
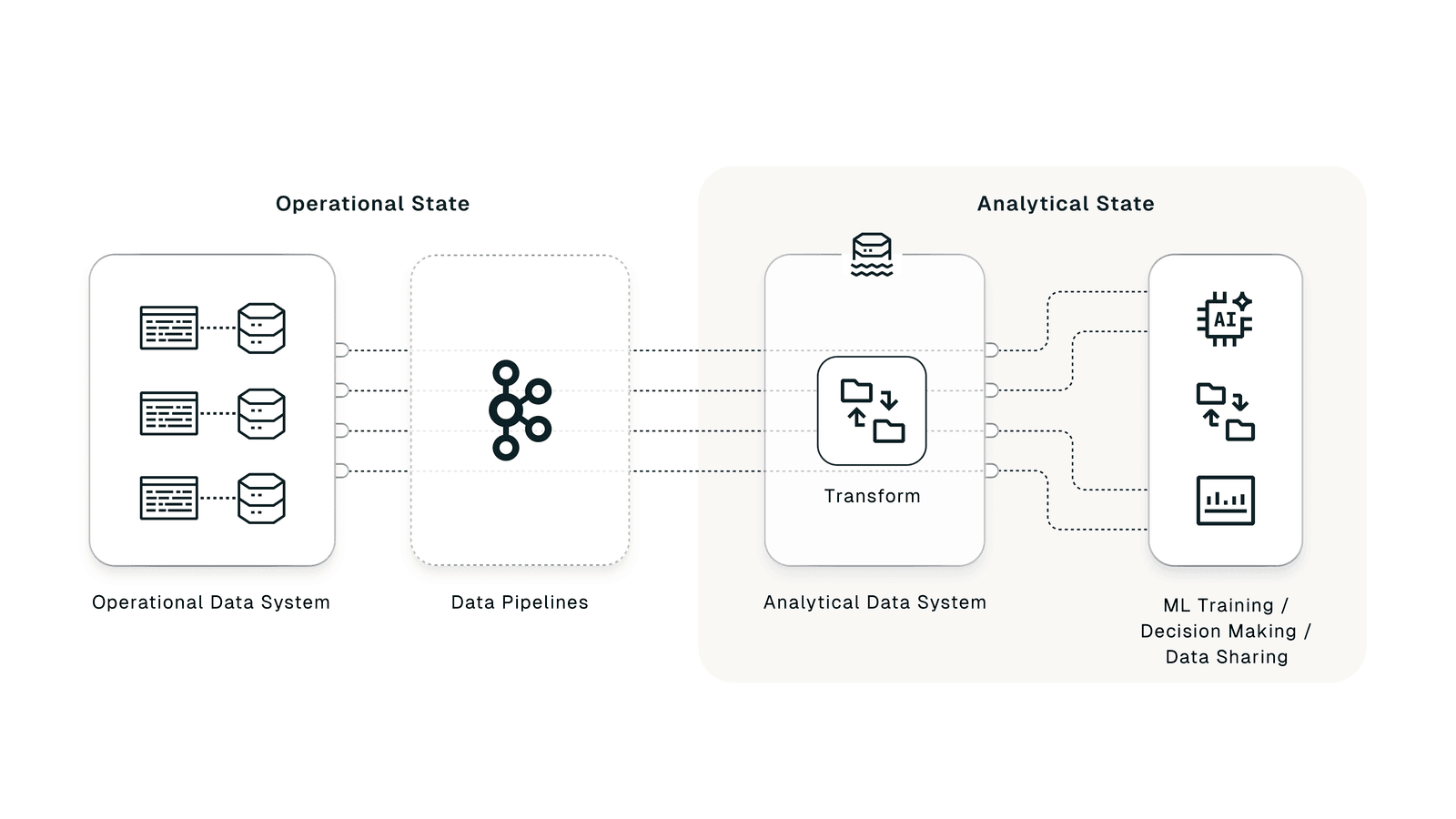
The Split Between Operational and Analytical Data
Two data worlds existed:
- Training data: transformed, structured, enriched
- Production data: raw, unfiltered, constantly changing
Unifying them would have solved the problem. But building a single operational-analytical model spanning streaming pipelines and data lakes wasn't simple. Data quality issues, fragmented ownership, and misaligned team priorities blocked progress. We managed it, but at high cost.
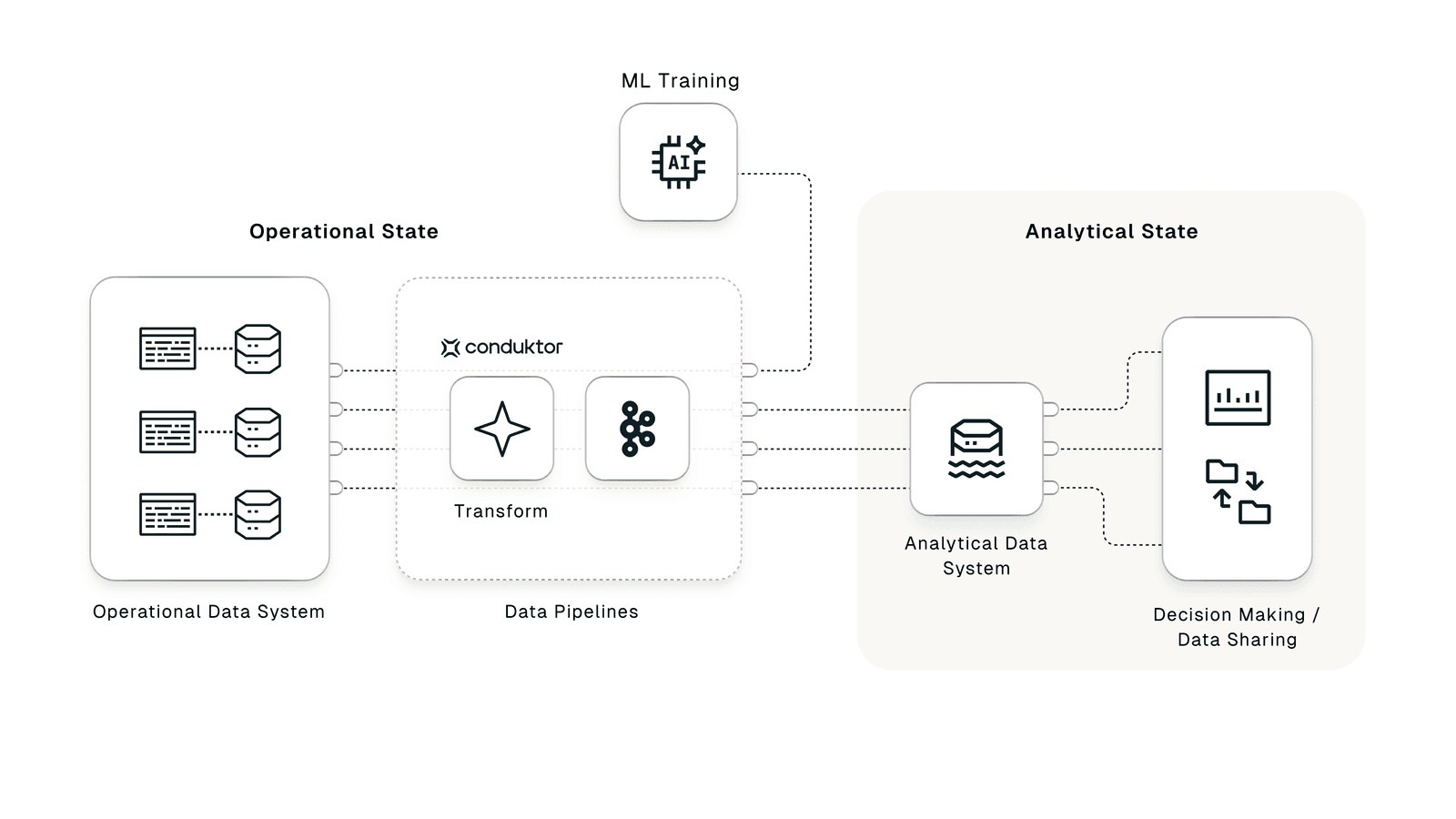
Enforcing Data Quality at the Source with Conduktor Trust
The real solution was shifting left: defining data standards and validations earlier, ideally within applications themselves. In a distributed microservice environment, that's expensive to implement and nearly impossible to govern without resistance. Developers resist added complexity. Centralized governance clashes with team autonomy.
Conduktor Trust solves this.
Trust lets teams define and enforce data rules at the source. It tracks anomalies, enforces structure, and guarantees field-level data quality before bad data enters streaming pipelines or data lakes. This maintains a consistent data model across both analytical and operational environments.
With Trust, we could have caught inconsistencies before production. Models would have trained and deployed on the same data structure. No wrapper logic. No patchwork fixes. Faster iteration with reliable results.
Why I Joined Conduktor
That experience taught me how fragile data systems become when teams operate in silos. It also showed me how valuable a solution like Trust could be.
I joined Conduktor to help build tools I wished we had. Trust gives data engineers, developers, and analysts a common foundation for clean, reliable data.
If you're facing the same training-production disconnect, look at Conduktor Trust or sign up for a free demo.