Kafka's Real Problem Is Governance, Not Speed
Most Kafka clusters push less than 1MB/s. The challenge isn't throughput—it's building the control plane that makes streaming usable at enterprise scale.


For a decade, we've obsessed over benchmarks, p99s, and GB/s. But look inside the clusters that run real businesses, and you'll see a different story. Kafka's biggest challenge isn't technical: it's human.

Throughput has become a poor measure of success. As an engineer, I love elegant systems. But I'm no longer impressed by endless benchmark wars about throughput, latency, or synthetic datasets.
From my time working with large enterprises, I've learned that those numbers barely matter. Most Kafka clusters aren't massive data engines. They're small, strategic systems connecting hundreds of interdependent applications. It's often treated as pure infrastructure: something you deploy once, give access to all your developers, and expect to quietly deliver value from day one. That couldn't be further from reality. Kafka grows with the organization. It's a living system that spreads across teams and environments, changing as the company evolves.
I've seen large migration programs to Kafka run for six months, only to stop and roll back. Was Kafka performance to blame? Absolutely not.
The best explanation I've heard comes from Filip Yonov at Aiven, who's running an environment of 4000+ Kafka clusters. In Kafka's 80% Problem, he explains that most Kafka deployments push less than 1MB/s. Kafka is not about raw speed. It's about coordination at scale.
Why Throughput Metrics Miss the Point
Kafka built its reputation on speed. Every benchmark, every slide, every blog post highlights throughput and latency. If you don't believe me, just do a Google search on "Kafka benchmark." Yet, when you look at production clusters of common businesses, most aren't pushing GB/s.
The statements you hear:
- "Our p99 is lower"
- "Our producer latency is faster"
- "We handle millions of messages per second"
I get it. It's enjoyable to run kafka-producer-perf-test.sh on your machine and see:
3556911 records sent, 711382.2 records/sec (694.71 MB/sec), 0.4 ms avg latency, 6.0 ms max latency.
But only a handful of companies truly operate at hyperscale: Netflix, LinkedIn, Uber, New Relic, Slack, Pinterest, Criteo, OpenAI, and Datadog. They either have enormous user bases or process oceans of logs and telemetry. Are you, like LinkedIn, processing 7 trillion messages per day? Probably not.
99% of businesses don't run at hyperscale. They operate in financial services, retail, healthcare, logistics, domains where systems move at a human rhythm. In those worlds, 5,000 records/s or 20 MB/s is already a meaningful load. Aiven's fleet (4,000+ Kafka services) shows a median ingest rate of around 9.8 MB/s.
Even that number lies. Most of Kafka's so-called "throughput" isn't application data at all. It's infrastructure traffic:
- Replication between brokers
- Cross-cluster sync for DR or multi-region setups (MirrorMaker, Replicator, Cluster Linking)
- CDC streams from databases (Kafka Connect, Debezium)
- Derived data from stream processors (Kafka Streams, state stores)
- Internal logs and metrics
The true business data (orders, payments, messages, transactions) is just a tiny fraction of the total. It's like judging a city's traffic by counting delivery trucks instead of people. For most companies, Kafka isn't about speed. It's the backbone for moving operational data safely between teams and systems.
As an aside, the ultra-low-latency world uses other tools entirely:
- LMAX Exchange in High-Frequency Trading (HFT), talking less than one microsecond
- ARINC 429 in aviation
- AUTOSAR in automotive
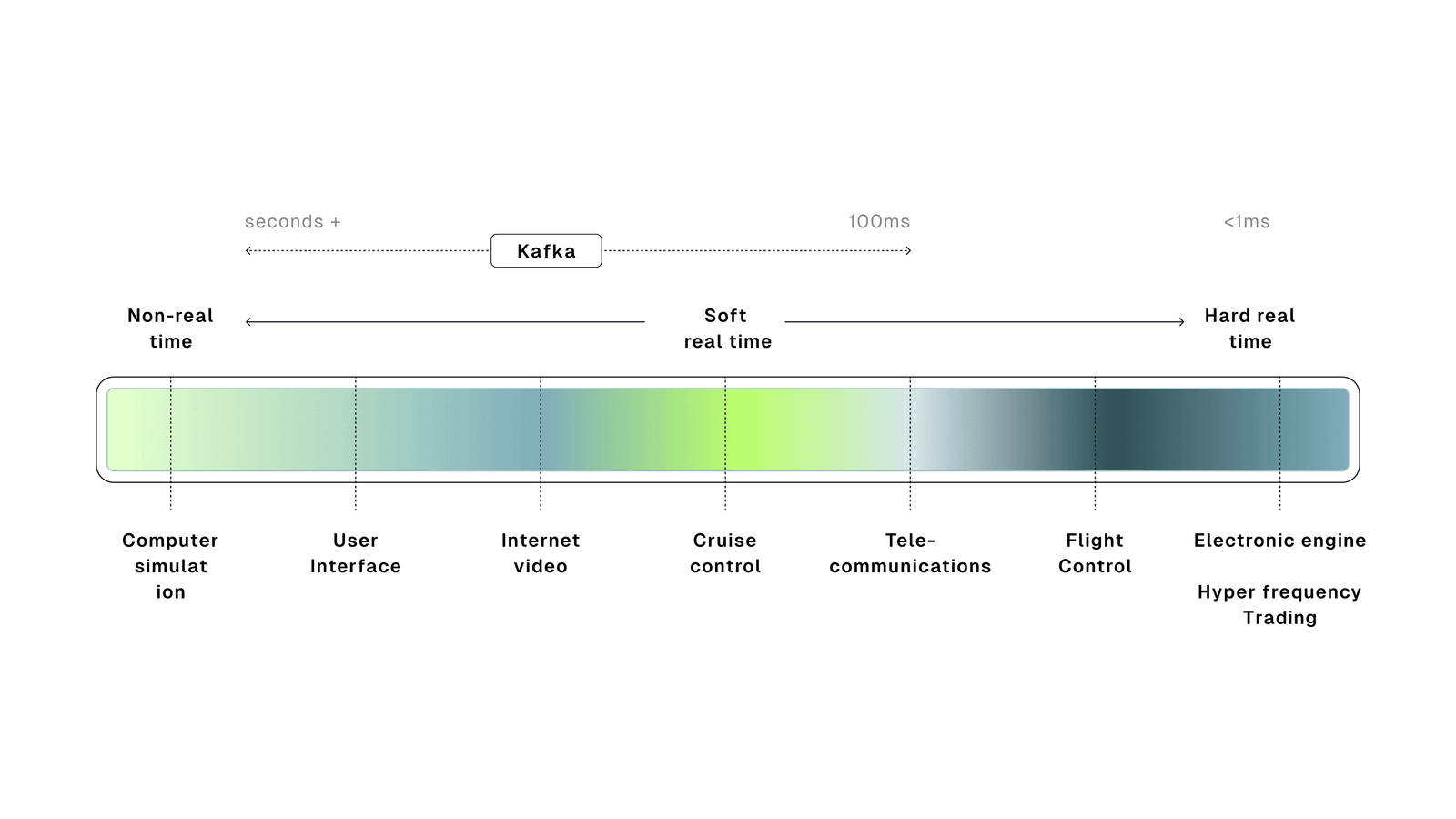 Kafka was designed for reliability and coordination, not microsecond latency
Kafka was designed for reliability and coordination, not microsecond latency
Why Platform Teams Struggle with Kafka Adoption
Kafka provides a robust foundation for event-driven architectures. But most organizations overestimate the value of deployment alone.
Many assume that simply deploying it will deliver value, and when it doesn't, someone will blame Kafka for "not working." Next, they'll suggest migrating to Pulsar or NATS, but the same problem will follow. The real challenge isn't Kafka. It's the lack of a control system around the data environment. That's where platform teams come in, building what Gartner calls a "Digital Platform": a control layer that turns raw infrastructure into usable capability.
Some relevant stats:
- 43% of organizations have been building platform teams for the past three years.
- Over 55% of those teams are less than two years old, evidence of their early positions on the maturity curve.
These teams work hard to provide clusters, access controls, connectors, and monitoring, but they still struggle with developer adoption:
- Your #kafka-platform-dsp Slack is flooded with questions
- You have a ton of ServiceNow tickets to help with Kafka application troubleshooting
- You are relying on your favorite Kafka provider (or ticketing system) to support you
- Some teams copy preset configurations, while others look for 'Kafka experts' to optimize their batch size or reduce their app latency
- Everybody blames Kafka for being complex
Kafka doesn't fail because it's slow. It fails because it's unmanaged. Control, not throughput, defines maturity.
If I hand you a Ferrari 488 Pista or a McLaren 720S, could you drive it full speed without crashing at the first turn? Probably not. Not because the car lacks power, but because there's no control system keeping you on the track. The same applies to streaming: without governance, every turn is a drift.
A control plane for streaming environments doesn't move data. It creates clarity, defines ownership, enforces rules, and provides feedback loops for producers and consumers. It exposes a useful, simple, human, and applicative layer for collaboration and safety.
That's what OpenAI understood early. They wrapped Kafka behind proxy-based control planes, making usage safe, auditable, and scalable. They're applying the same principle to Flink.
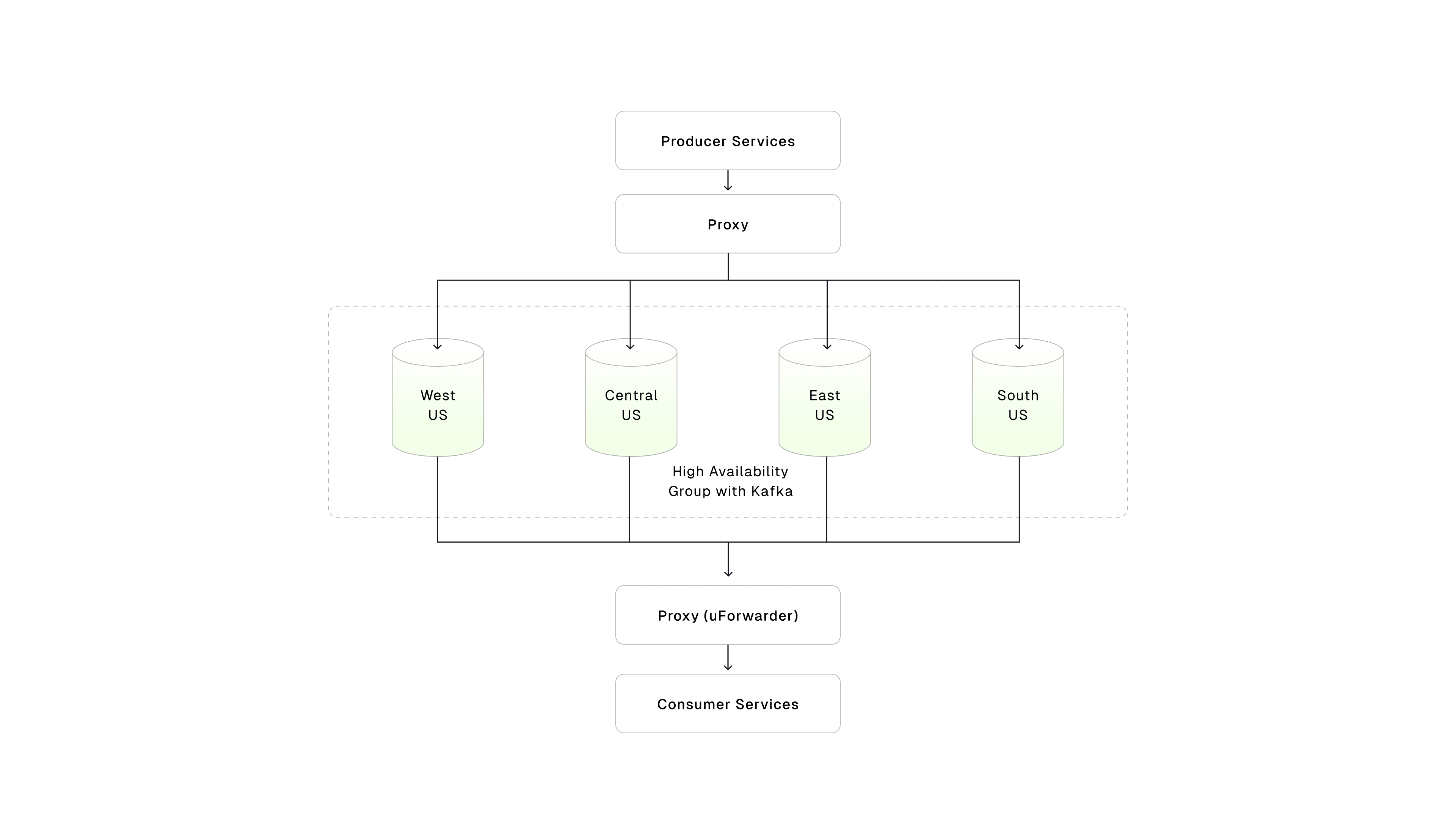 Illustration inspired byByte Byte Go.
Illustration inspired byByte Byte Go.
What Happens When Kafka Scales Without Structure
Scaling Kafka isn't about partitions or brokers. It's about people and teams. Things work fine when ten applications talk to each other. They start breaking when there are a hundred.
Teams begin inventing their own conventions: JSON vs. Avro vs. Protobuf, topics with dashes or dots (sometimes versioned, sometimes not). PII flows freely. Your governance team is setting up things on Collibra months later, without the developers in the loop. Nobody knows what's authoritative.
Most platform teams take a stance of non-interference. "We just provide Kafka as a service. It's up to teams to use it how they want. We don't want to dictate data ownership, we just provide the pipes."
It sounds noble. It's also a guaranteed path to chaos. I know because I've been there.
A control plane keeps alignment and synchronizes how humans use Kafka, not just how data flows through it:
- Making configuration and ownership visible
- Applying security and data policies automatically
- Giving platform teams usage metrics and reverse telemetry
- Reducing friction without removing guardrails
The real maturity metric isn't records/second. It's how easily new applications can join the ecosystem without breaking anything. When you zoom out from a single cluster to an entire ecosystem, Kafka isn't just a tool: it's a medium for human coordination.
Shifting from Data Plane to Control Plane Thinking
We've entered a new phase of streaming systems. The question is no longer "how quickly can we move more data?" It's "how safely and consistently can we move data across hundreds of apps and teams?"
At enterprise scale, culture and context must be encoded into the system. That's Control Plane Thinking: shifting the focus from "make Kafka faster" to "make Kafka usable." Reliability isn't built in code. It's built in how humans negotiate change.
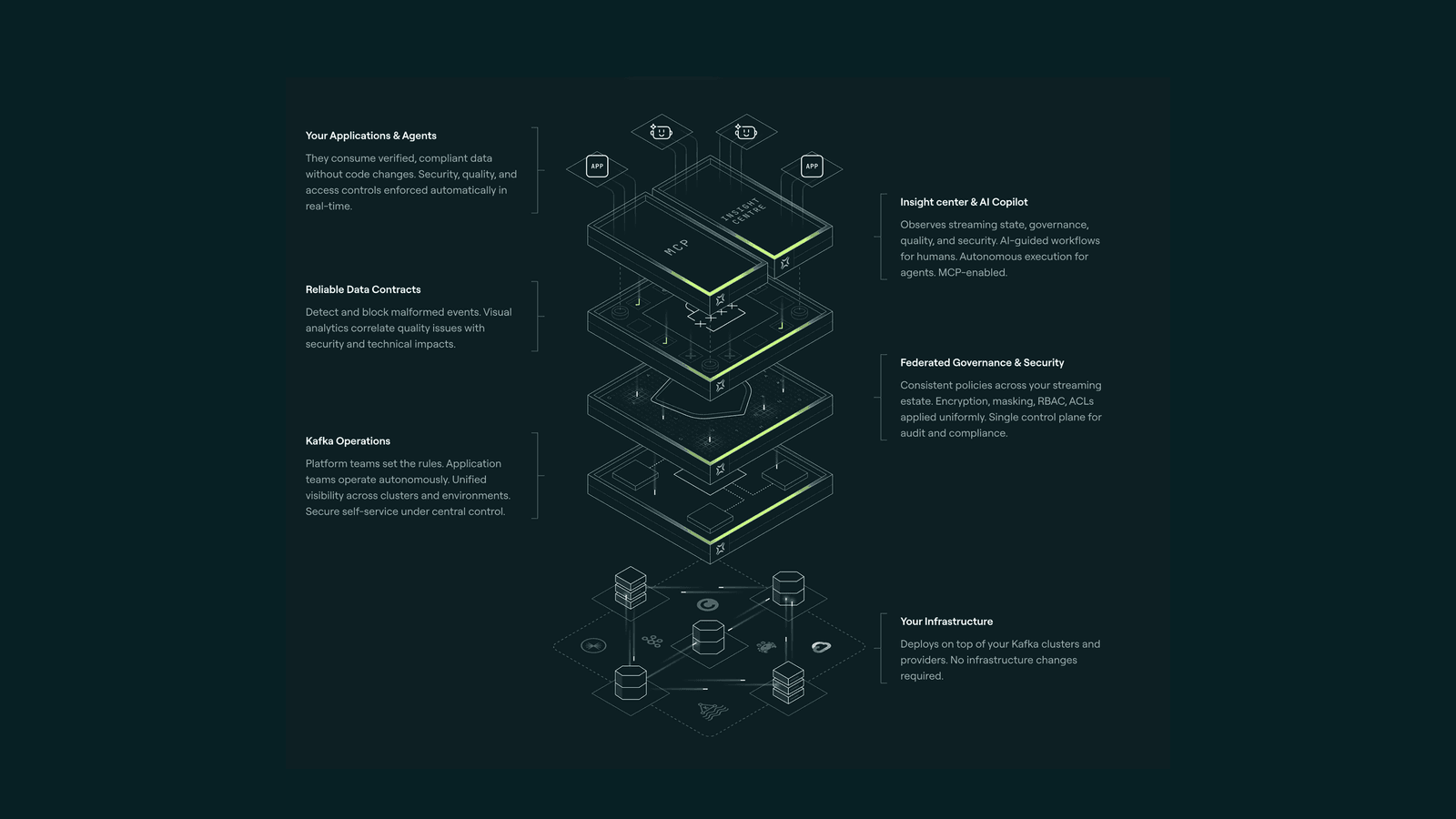 The Conduktor Kafka control plane
The Conduktor Kafka control plane
Streaming used to be a niche infrastructure topic. Today it's the nervous system of the enterprise. AI pipelines, microservices, analytics, and monitoring all depend on a reliable streaming backbone.
In a recent study from Confluent, 86% of IT leaders see data streaming as a strategic priority (thanks to its role in AI, analytics, and microservices), but they also emphasize the need to "shift left": embedding quality, security, and compliance early in the data streams.
Managed cloud services (Confluent Cloud, AWS MSK, Aiven, Redpanda) have made Kafka easier to deploy, but not necessarily easier to work with. We still need a layer that bridges human and technical realities:
- Central visibility across clusters
- Policy propagation
- Schema and data-contract validation
- Integration with identity systems
We're entering the age of streaming governance, not as a checkbox, but as part of the infrastructure itself. This market is expected to grow from $4.68B to $22.87B over the next eight years.
The Real Metric Is Trust, Not Throughput
We don't need faster Kafka clusters. We need smarter ones.
Throughput is a vanity metric. Adoption is the real one.
As CTOs and platform leaders, our job is no longer to tune brokers or chase p99s. It's to design the control systems that make streaming usable, safe, and scalable for everyone in the company.
The next decade of data engineering won't be defined by throughput. It will be defined by trust and control. Because in the end, speed means nothing without control.