How to Handle Large Records in Kafka Without Killing Performance
Bypass Kafka's 1MB limit without performance hits. Use S3 cold storage with claim check pattern for PDFs, images, and massive batches—seamlessly.


Apache Kafka started as a "technical pipe" for distributing data between applications. It has since become the backbone of enterprise data architecture.
Kafka's real power is how it changes organizational data culture. Data becomes a shared resource, a common language across teams. This enables better decisions, operational efficiency, and innovation.
But Kafka has a hard constraint: the default record size limit of 1MB (see our Kafka Options Explorer with message.max.bytes). You can increase this limit, but doing so requires updating many related configurations.
Common Use Cases for Large Data in Kafka
Kafka is byte-agnostic. It processes whatever you send: text, JSON, Avro, Protobuf, or:
- CSVs from ETL pipelines
- PDFs (common in enterprise data flows)
- Large images in healthcare or traffic monitoring
- Video chunks for processing or intrusion detection
- Audio files
- IoT sensor data
- Machine learning models
The question: how do you process large records while respecting Kafka's technical limits?
Why Large Records Destroy Kafka Performance
Large records cause serious problems:
- Kafka storage is expensive. With replication.factor of 3 or 4, you duplicate every large record 3-4x.
- Large messages extend broker restart times, reducing reliability.
- They dominate broker resources due to Kafka's threading model.
- They require many behind-the-scenes configuration changes. The full impact is hard to predict.
Sending large records to Kafka is a bad idea. It opens Pandora's box.
But business requirements exist. You need a solution.
The Claim Check Pattern with AWS S3
Chunking large messages at produce-time and reassembling at consume-time is a terrible idea. Everyone knows this.
The real solution: the Claim Check Pattern.
How it works:
- The application sends large data to cheap storage like AWS S3
- S3 returns a unique reference
- The application sends that reference into Kafka instead
- Consumers retrieve the reference and fetch the data from S3
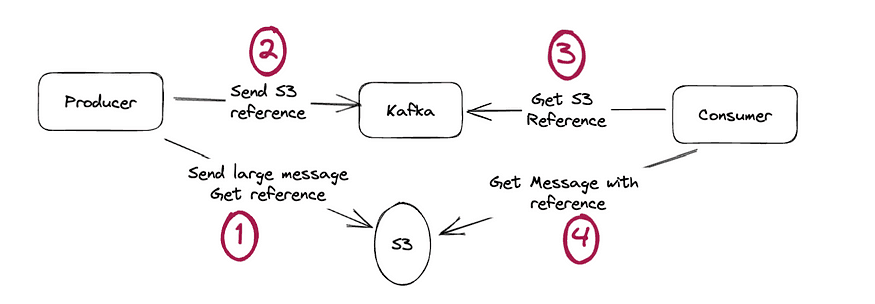
This bypasses all large record issues. What goes into Kafka is a simple string like "s3://mybucket/myfile.pdf". Minimal payload.
The problem: governance. Every application needs S3 access credentials, secret management, and password rotation handling.
This seems fine when you know all your producers and consumers. But as Kafka spreads across business units, governance becomes a nightmare.
Transparent S3 Offloading with Conduktor Gateway
Our S3 Cold Storage plugin implements the claim check pattern transparently. Applications change nothing. They send large messages normally. Magic happens.
Conduktor handles all S3 operations and governance. Applications have no idea what's happening. It's all behind the scenes.
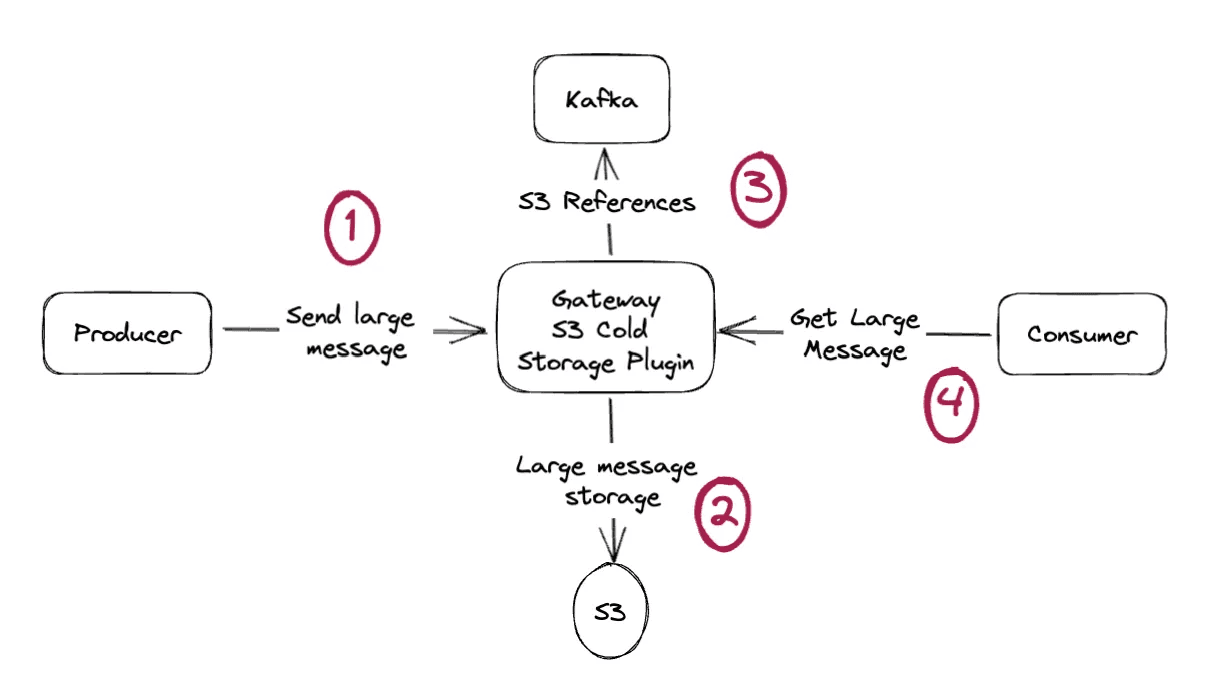
Kafka never stores large messages. Producers and consumers keep sending and receiving large messages seamlessly through Conduktor.
Results:
- Kafka storage problem eliminated
- No large record duplication in Kafka
- No performance or reliability penalty
Handling Large Batches, Not Just Individual Records
The previous examples focused on individual records. But Kafka operates on batches of records.
Say you're ingesting logs or telemetry at tens of thousands per second. You've followed best practices: configured linger.ms, large batch.size, compression.codec.
With this volume, your application hits the batch.size limit constantly. Performance suffers.
You face all the same drawbacks. You optimized configuration for throughput, but now you're storing large amounts of data in Kafka. Expensive for network, storage, and reads.
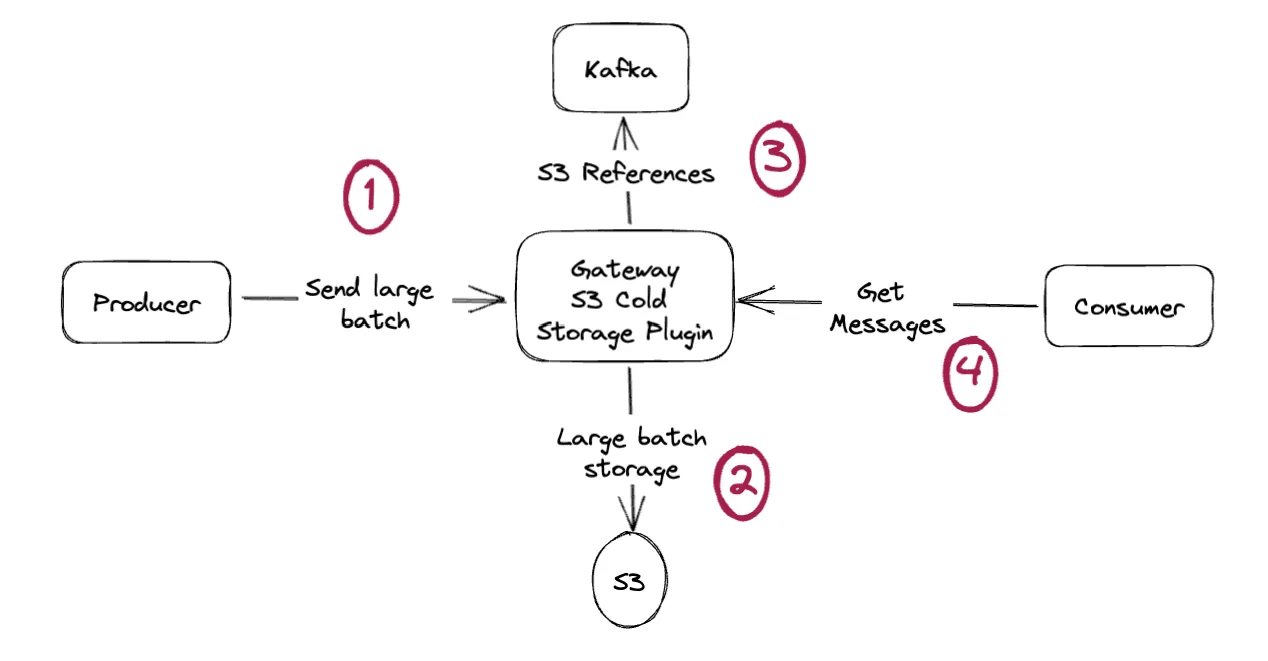
Solution: apply the claim check pattern to entire batches, not just individual records.
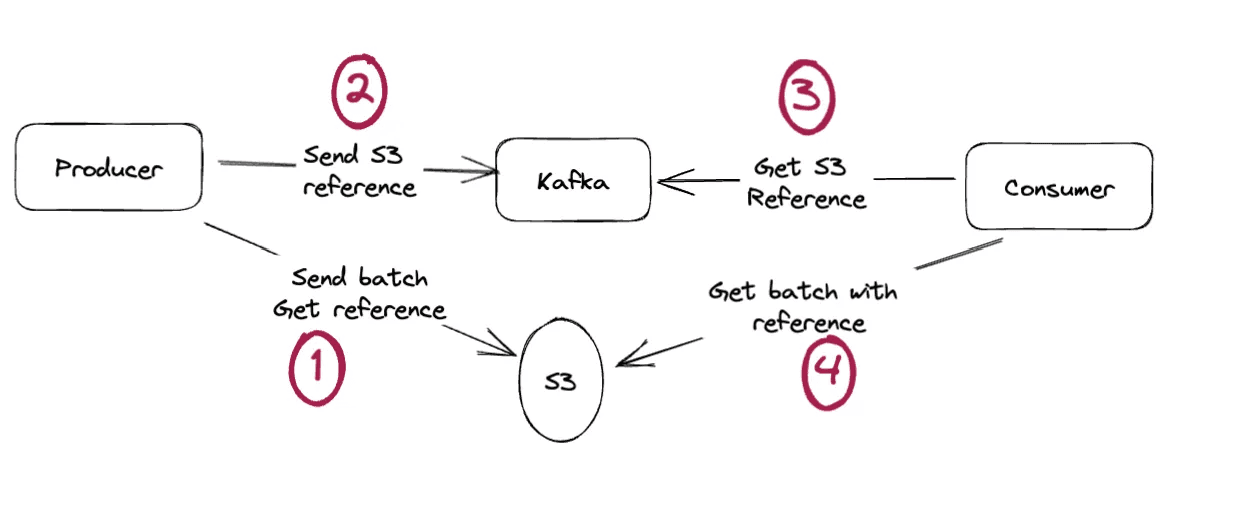
Kafka doesn't expose batch operations (steps 1 and 4). Record batches are internal, inaccessible, sensitive.
Conduktor does it. Send a whole batch to S3, store one file reference in Kafka. Consumers receive records one-by-one on poll(), unaware of the offloading.
State Explosion: The Hidden Risk in Every Kafka Application
You might think: "I don't have this problem. I don't need claim check."
Consider this exercise:
You have a Kafka Streams word count application. The simplest Kafka Streams example: WordCountLambdaExample.java
Everything runs smoothly. You have word counts. Kafka Streams stores every word and its count.
Now change the requirement: add contextual information for each word. Position in sentence, location on page, chapter name.
Now you have a problem. Common words accumulate massive state. They'll hit Kafka's message size limits fast.
This highlights state explosion. It happens in Spring applications, Kafka Streams, everywhere. Data size depends on business reality, not your design:
- E-commerce: a user orders hundreds of items. Your 'order' becomes a multi-megabyte JSON.
- Support tickets: too many comments. Multi-megabyte JSON.
- Like systems: thousands of user IDs in arrays. Megabytes.
In production, your application halts. Can't emit messages. Pods restart. Users complain. Panic.
After investigation, you and Ops find the problem: messages too large. As a fix, you manually increase the maximum message size for that topic.
You restart producers. It works. But now consumers struggle with large data (longer load and process times). Your Kafka infrastructure pays the price.
The real problem isn't Kafka. It's a design flaw that takes time to fix. Your quick fix could hold you back.
Conduktor handles this:
- Moves messages to S3 seamlessly
- Protects Kafka infrastructure and performance
- Alerts in the audit log when this happens
- Buys you time to fix your application design
Message Size Limits in Managed Kafka Services
Cloud providers managing your Kafka often won't let you set arbitrary batch sizes:
- Azure Event Hub for Kafka: maximum 1MB. Need 1.1MB? Too bad.
- AWS MSK: maximum 8MB. Need 8.1MB? Problem.
- Confluent Cloud: 8MB on Standard, up to 20MB on Dedicated.
What about performance and resiliency? What if you need more?
Summary
Conduktor's S3 Cold-storage plugin offloads data to:
- Protect your Kafka infrastructure and performance
- Avoid governance and security complexity
- Enable capabilities that don't exist in native Kafka
- Save money
- Handle unexpected situations while you fix the root cause
Contact us to discuss your use cases. We're Kafka experts building out-of-the-box solutions for enterprises.
You can also download the open-source Gateway (enterprise features not included) and browse our marketplace for all supported features.