Real-Time Kafka Data Is Your AI Competitive Advantage
Real-time, trusted data is the new AI advantage. Discover why the future belongs to companies that treat data as a product, not a by-product.


Data is your competitive moat, but only if you trust it. The winners in the AI era won't be those who collect the most data. They'll be the ones who govern it, activate it in real time, and make it available the moment their models need it.
The future of AI depends on building trust at the source. Modern data leaders are operationalizing real-time data as a strategic product.
Treat Data as a Product, Not a Cost Center
Agentic AI doesn't want batch data. It needs clean, compliant, contextual information arriving in real time. That kind of data doesn't just support better models. It creates a strategic advantage.
Most organizations still treat data as a by-product: archived in warehouses, delayed by manual approvals, or stuck behind compliance bottlenecks.
In the AI economy, real-time, governed, first-party data is the pickaxe. The companies that own it won't just survive the AI boom. They'll power it.
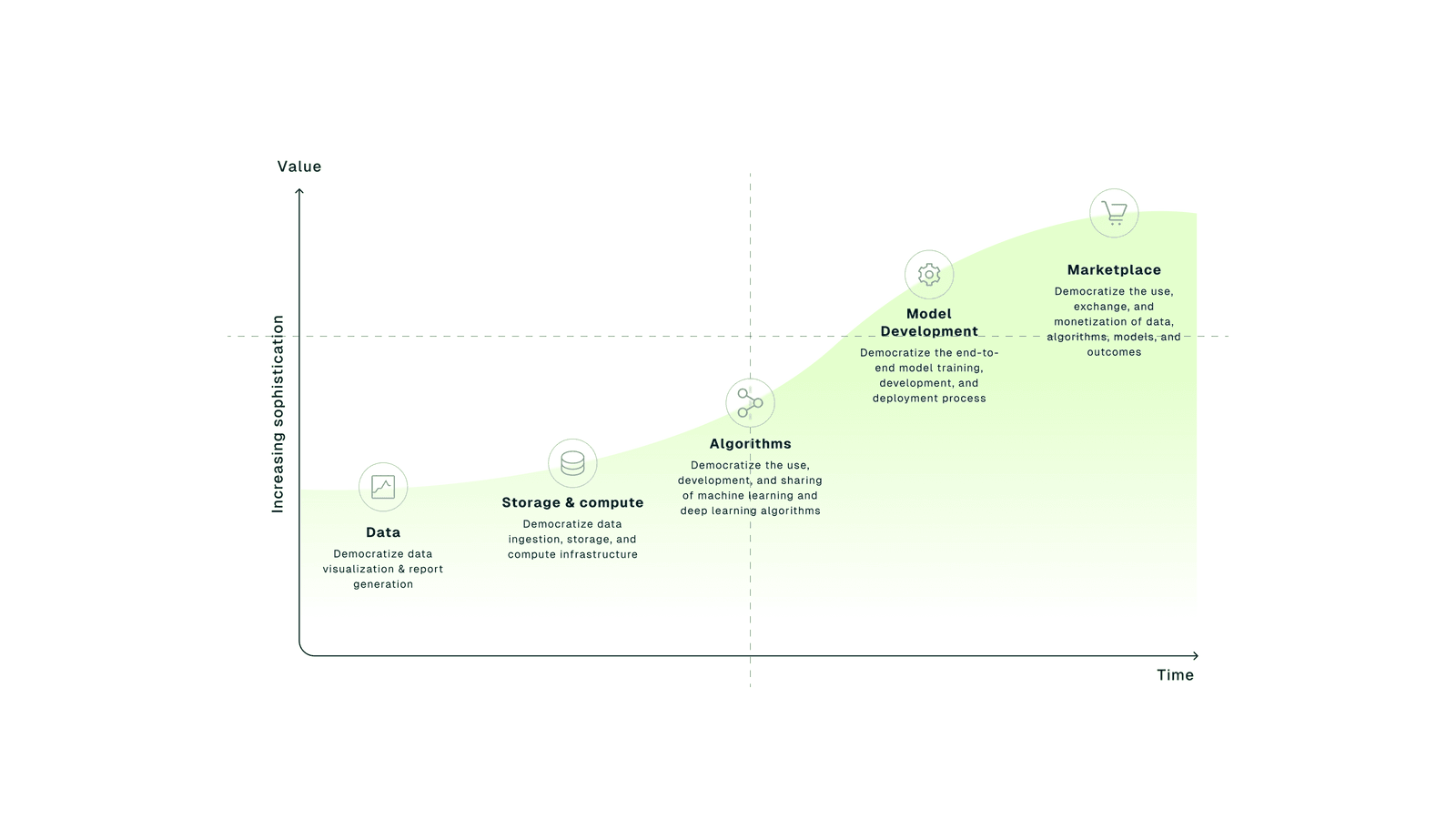
The Three Stages of Data Monetization
This is the third article in our series exploring how enterprises transform data streams into revenue streams. From infrastructure readiness to scaling and governance, this piece focuses on how data becomes monetizable when treated like a product.
Turning data into competitive advantage requires mastering three core stages:
1. Create: Activate data in real time to trigger workflows, power contextual AI, and prevent data from going dark. Your warehouse stores history, but your event stream drives business. Read the first blog post in this series.
2. Scale: Grow without breaking things. Ensure quality, consistency, and governance across environments. Throughput means nothing if no one trusts the output. Read this blog post to learn more.
3. Monetize: Turn first-party Kafka streams into competitive advantage, whether you're feeding private AI models, building internal copilots, or selling clean, real-time data to partners.
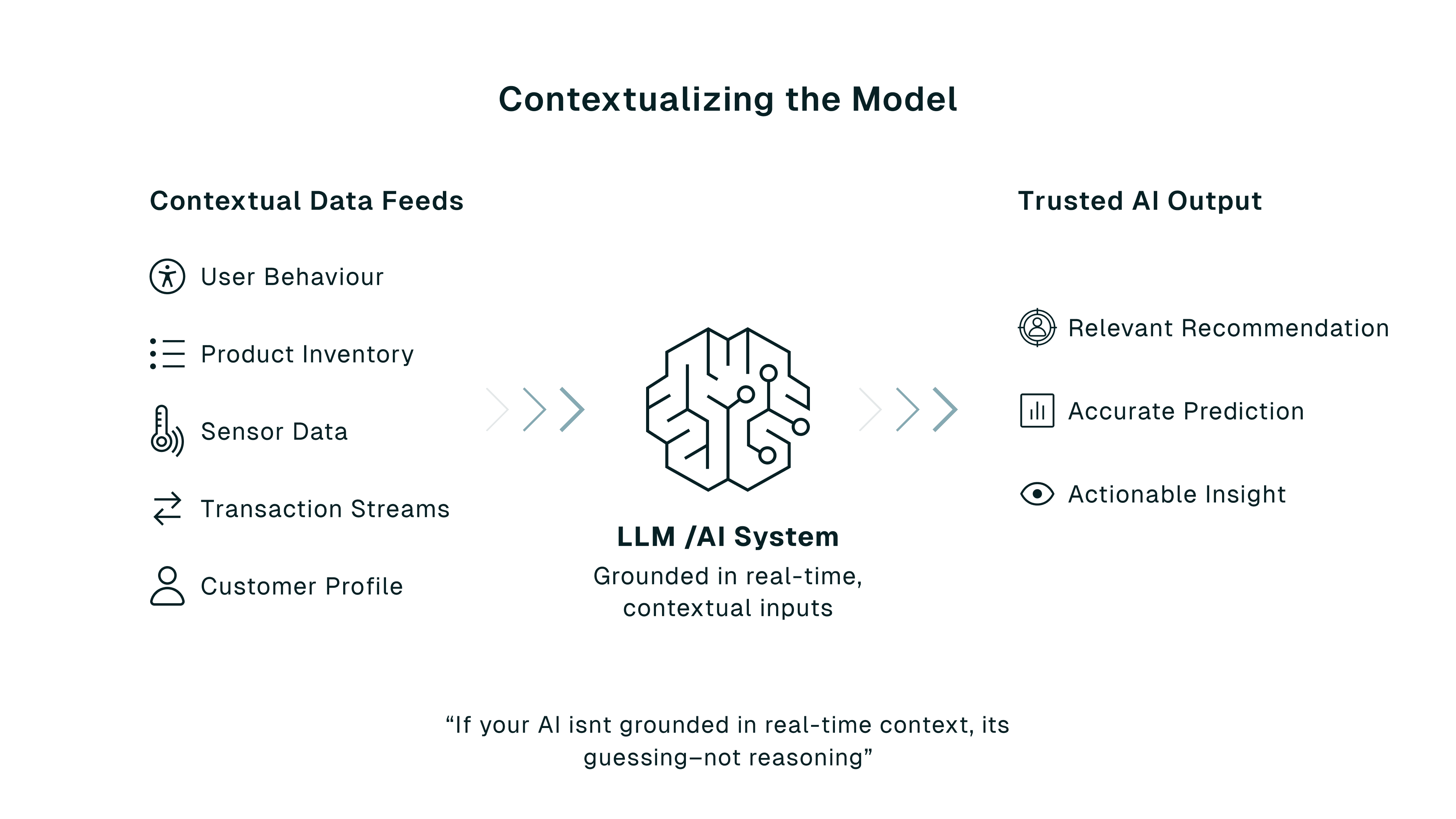
AI Models Need Context, Not Just Data
Today's AI doesn't just need information. It needs understanding, which is only possible with contextual data.
Without context, an AI model guesses based on generic signals. With context, it reasons based on real-time signals that reflect your actual environment, customer, or event.
Whether you're generating a product recommendation or detecting fraud, the who, what, when, and where matter. LLMs respond better when grounded in:
- Real-time user behavior (vs. a static profile)
- Live inventory data (vs. outdated catalogs)
- Fresh financial transactions (vs. yesterday's batch report)
Context makes AI relevant. It's the difference between a generic answer and the right one.
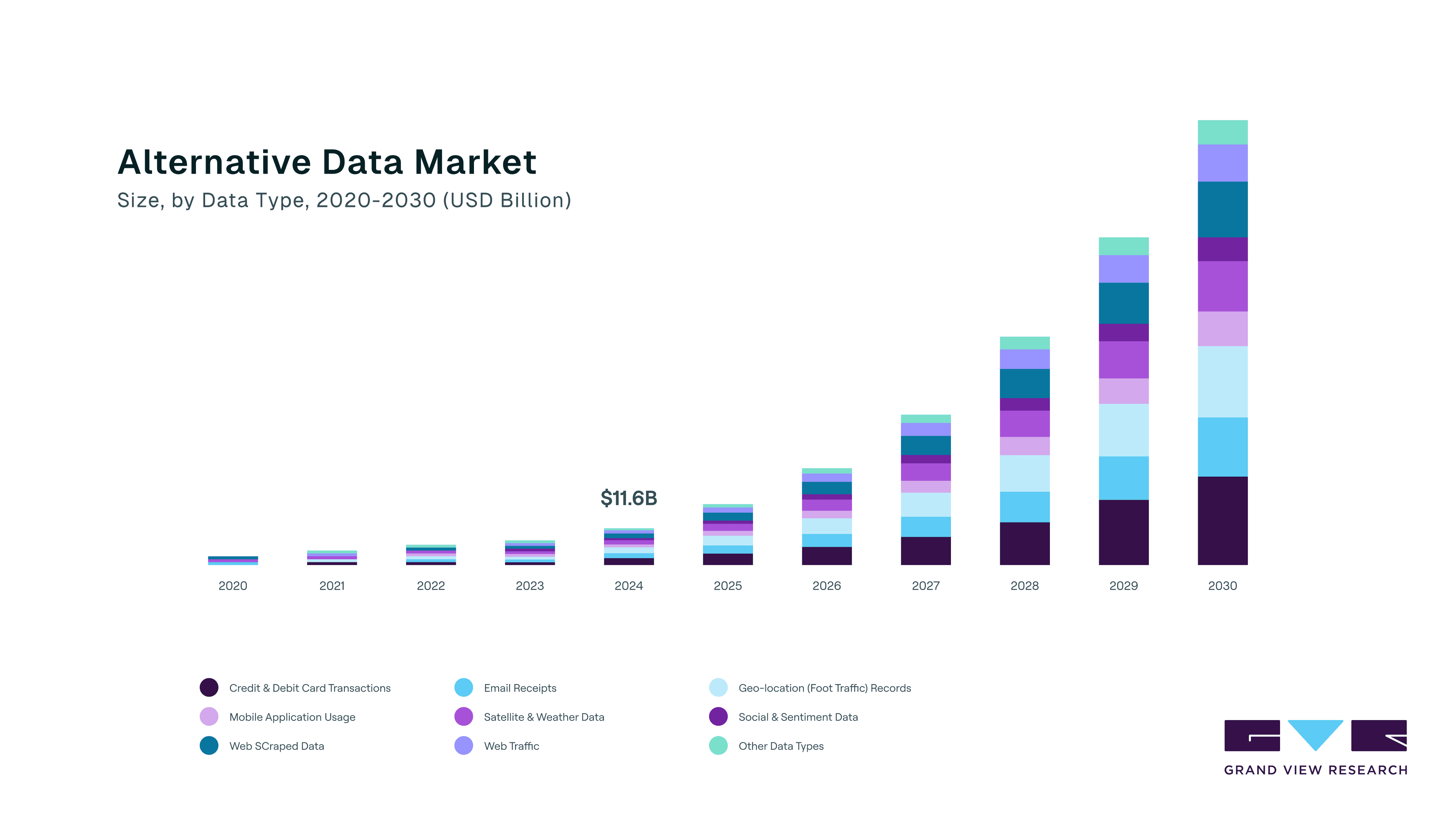
Freshness, Ownership, and Compliance Define High-Value Data
Not all data is created equal. In the GenAI era, model performance depends on the uniqueness, freshness, and reliability of your data.
The new standard for high-value, AI-grade data:
- Real-time ingestion
- First-party ownership
- Security and compliance by design
Batch data can't keep up. Third-party data is commoditized. The alternative data market, which thrives on real-time, non-traditional streams, is projected to grow at over 50% CAGR through 2030.
Kafka gives you the pipeline. Governance, trust, and secure sharing turn that into a product.
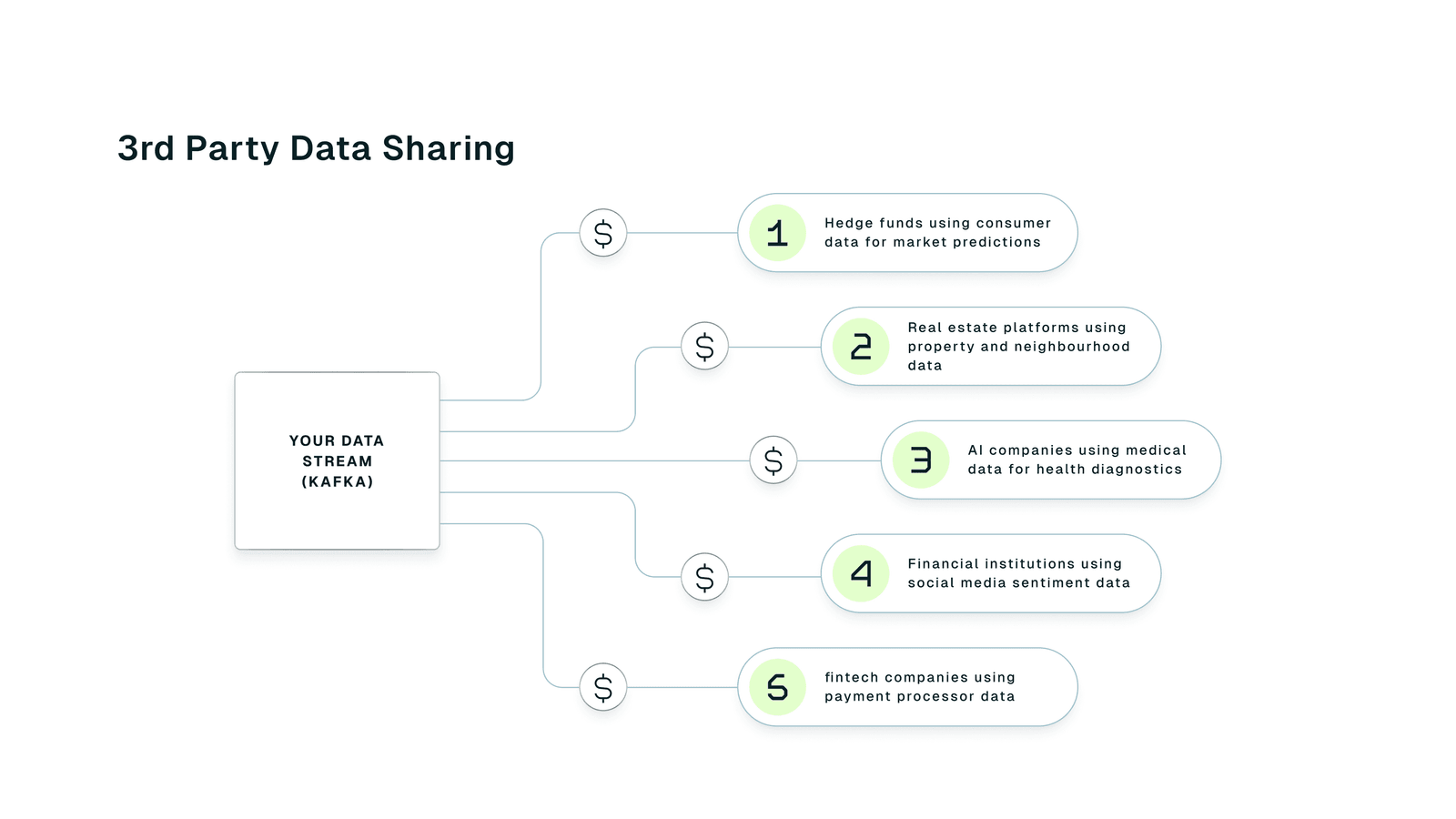
How Finance, Retail, and Logistics Monetize Their Kafka Streams
Forward-thinking companies aren't just managing Kafka. They're monetizing it.
- Finance: Hedge funds pay for millisecond-level market data. It's the edge they trade on.
- Retail: Big-box stores stream live purchase data to brand partners for smarter demand forecasting.
- Logistics: Carriers like FedEx and UPS sell visibility and live tracking data to platforms and customers.
- Telecom: Carriers share usage data for real-time personalization and network optimization.
- Energy: Utilities offer real-time grid usage data to pricing engines and energy marketplaces.
These aren't pilot programs. They're proven revenue strategies built on streams you already own.
Using Data Internally Creates Competitive Advantages Competitors Can't Replicate
Selling data is just one side of monetization. The real power is using data to outmaneuver competitors: fueling AI, optimizing operations, and creating new revenue streams that others can't replicate.
- E-commerce players tune relevance on the fly using clickstream and behavior data.
- Manufacturers predict demand with sensor data and optimize before problems hit.
- Healthcare platforms detect anomalies in real time, improving care and reducing fraud.
- AI-native companies refine proprietary LLMs with live, owned data nobody else can access.
You don't need to sell your data to profit from it. Owning it and using it intelligently can be the ultimate advantage.
First-Party, Real-Time Data Commands a Premium
Winning in the AI era isn't about collecting information. It's about curating clean, structured, real-time datasets that power models instantly.
- First-party data is the new moat. If you own the data, you control access and the price tag.
- AI-ready data commands a premium. Raw, unstructured, or outdated data holds little value. Real-time, structured, contextual data is worth its weight in gold.
- Security and compliance matter. The most valuable datasets are safely shared, ensuring GDPR and CCPA compliance while maintaining customer trust.
Companies sitting on first-party, real-time data are in the strongest position. While everyone else scrambles for external data, they own the pickaxe in the AI gold rush.
Governance Must Happen Upstream, Not After the Fact
The gold rush metaphor still resonates: the biggest winners weren't always the ones mining for gold. They were the ones controlling the tools, infrastructure, and supply chain around it.
In the AI economy, real-time, first-party data plays that same enabling role. Unlike physical commodities, data can't just be collected. It needs to be curated, secured, and governed in motion. Today's AI models require freshness, relevance, and reliability.
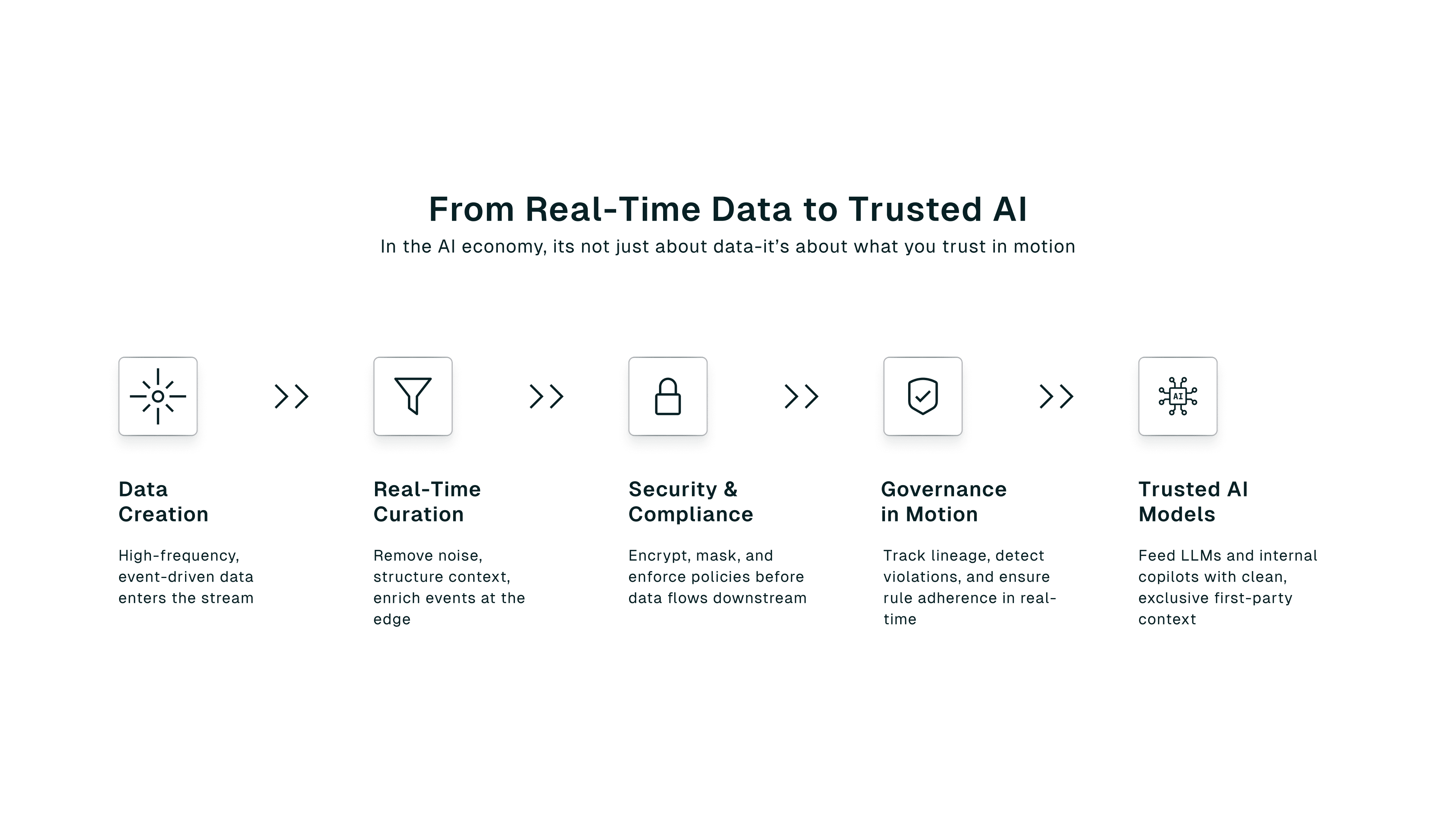
Trust in your data can't be an afterthought. It must be enforced upstream, continuously and automatically. That means building systems that enforce data quality before ingestion, apply fine-grained access control and encryption by design, and surface real-time policy violations and quality issues as they occur.
As data moves from raw to refined, its strategic value grows, but so does the complexity of managing it. Those who master this lifecycle, from ingestion to insight to monetization, gain a structural advantage.
The most valuable data is governed, high-quality, secure, and available the moment your model needs it.
Build Data Trust Into Your Architecture Now
The question isn't whether your data is valuable. It's whether you're treating it like a product, with quality controls, governance, and accountability built in.
AI models don't just need data. They need real-time context that's trusted, secure, and business-ready. Most organizations are still feeding their most critical systems with broken pipelines: batch loads, duplicated topics, schema drift, and zero visibility until something goes wrong.
This isn't a data volume problem. It's a data trust problem that starts with architecture.
We built Conduktor because teams needed a better way to treat streaming data like the strategic asset it is. That means enforcing quality upstream, managing access at the protocol level, and enabling secure data sharing without replication or governance rework.
The companies that win in AI won't just train bigger models. They'll architect trust into every stream, every topic, every decision.
Own the stream. Own the moat. The future of AI belongs to those who trust their streaming data.