Kafka Proxies, Cost Virtualization, and Flink: Takeaways from Current 2023
Key insights from Current 2023 and Big Data London: Kafka proxies for encryption, cost optimization through virtualization, and Flink's serverless future.


Conference Context
Conduktor attended Current '23 (the largest Kafka conference in North America) and exhibited at Big Data London, speaking at the new 'Fast Data' theatre.
We spent both events talking to companies about their data streaming initiatives. Here's what we learned.
Our Conference Talks
From POC to Mission Critical: Building a Fast Data Tooling Strategy
James and Stephane explored technical and organizational challenges that emerge as data streaming maturity grows.
Fast data enables organizations to extract greater value from the data flowing through their business. It's now pivotal to remaining competitive in all major industries. Despite this, many organizations fall into the trap of scaling fast data adoption without an underlying tooling strategy. Built on the foundations of a POC that eventually lands in production, few think longer-term about the challenges you will meet along the way. In this talk, we'll explore both technical and organizational challenges you will wrestle with as your fast data maturity grows to equip yourself to handle upcoming problems.
Squeezing the Most from Your Fast Data Infrastructure
Stuart explored problems that emerge from infrastructure expansion and solutions to mitigate them.
In the early stages, building your Fast Data strategy is easy and cheap: its scope is small, and things are moving fast. Engineers spend more time building pipelines, teams spin up extravagant resources and you find yourself and others routinely diverting their attention from your core business. In this talk, we'll explore the problems you'll experience from your infrastructure expanding and many clever solutions to mitigate them.
Why Kafka Proxies Resonated with North American Teams
This was our first chance to gauge in-person, North American market reception to Conduktor Gateway, our extensible Kafka wire proxy.
Conduktor Gateway is a Kafka proxy that sits between your client applications and existing Kafka cluster(s). It speaks the Apache Kafka protocol, so can be dropped into your existing infrastructure and your applications need only point to a new bootstrap server.
The question that followed was always "why?"
Kafka doesn't ship with controls you'd expect from enterprise technology, particularly around security and governance:
- No built-in end-to-end encryption. Your encryption strategy is only as good as your least informed client.
- Configuration sprawl. A rogue producer can cause havoc for everyone else.
- Audit gaps. As Kafka adoption grows, tracking which applications do what becomes harder.
End-to-end encryption consistently resonated most. We're in a world of data streaming and data exchange. Handling sensitive and PII data is unavoidable.
Kafka Cost Explosion and Virtualization
Cloud spending was a constant theme at both events, likely driven by inflation and geopolitical uncertainty. Multiple companies reported 3x managed Kafka spend within two years. Growth in data streaming adoption, yes, but also a clear need for cost mitigation.
Conduktor's virtual layer approach resonated as a solution. Similar to VMware for virtual machines, Conduktor virtualizes managed Kafka services, maximizing utilization of existing spend.
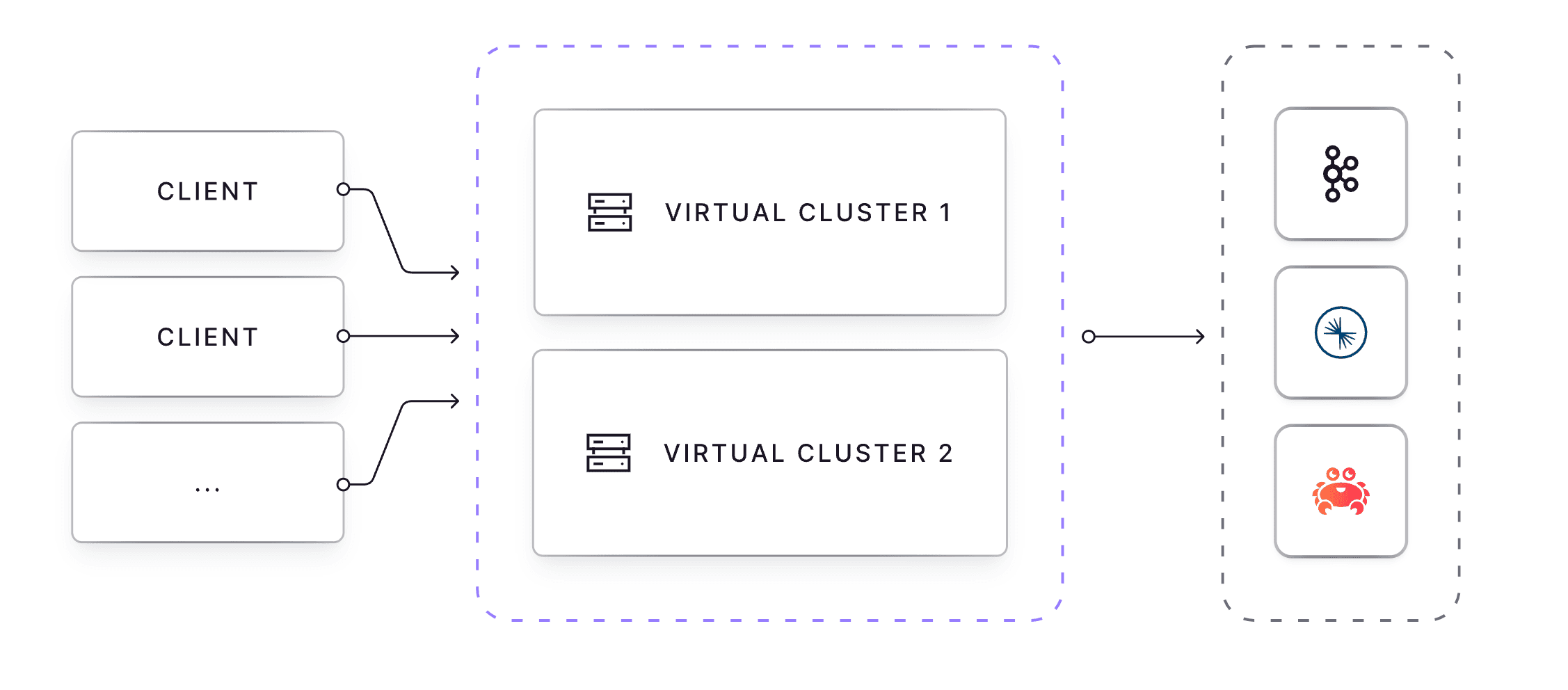
This vendor-agnostic layer increases utilization per cluster. It also enables data isolation (multi-tenancy with tenant-specific rules) and virtual topics via SQL statements for data projections, without deploying additional infrastructure.
Because Conduktor Gateway is Kafka protocol compliant, virtual clusters and topics function identically to real ones. Application teams can remain unaware of the abstraction.
Data Products and the External Data Sharing Gap
Confluent focused heavily on 'data products' in their keynote, showcasing their new data portal for democratizing internal data streams. It ties together data mesh principles: discovery, metadata, lineage, and domain-driven ownership.
Valuable for Confluent customers solving internal data exchange challenges.
But there was little emphasis on external data sharing, like real-time data with third-party partners. From our conversations, this remains a problem for most enterprises. The current solutions are painful ETL processes or expensive replication.
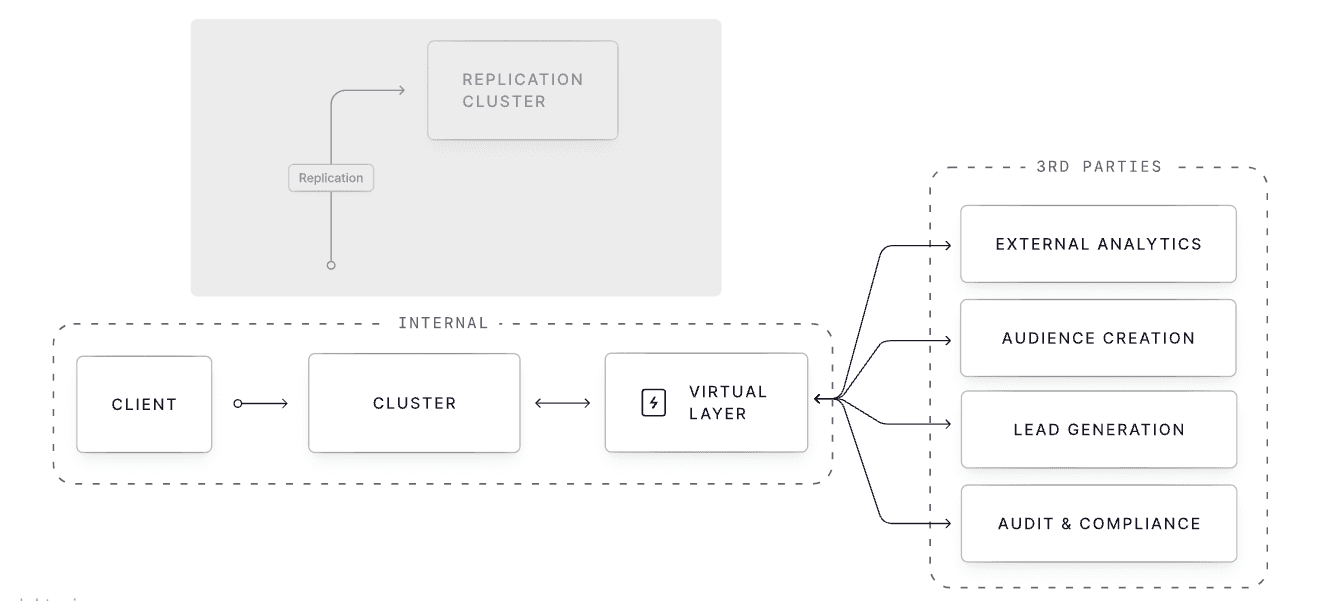
Snowflake has championed their marketplace for sharing warehouse data externally. Conduktor enables real-time sharing of Kafka data without replication overhead. Sharing a virtual view derived from the source-of-truth beats recreating the data.
Confluent's Bet on Serverless Flink
A dedicated 'Apache Flink Forest' at Current signaled Confluent's investment in Flink for stream processing, targeting both operational and analytical data estates.

Confluent's new offering will be the first truly cloud-native, serverless Flink service: automatic upgrades, auto-scaling, pay-per-use.
Whether Flink succeeds where ksqlDB arguably failed remains to be seen. We're watching.